
-
SOTA
-
Accelerator Toolkit
-
Deep Learning Toolkit
-
-
- Resume
- Add
- AlphaDropout
- AdditiveAttention
- Attention
- Average
- AvgPool1D
- AvgPool2D
- AvgPool3D
- BatchNormalization
- Bidirectional
- Concatenate
- Conv1D
- Conv1DTranspose
- Conv2D
- Conv2DTranspose
- Conv3D
- Conv3DTranspose
- ConvLSTM1D
- ConvLSTM2D
- ConvLSTM3D
- Dense
- Cropping1D
- Cropping2D
- Cropping3D
- DepthwiseConv2D
- Dropout
- Embedding
- Flatten
- ELU
- Exponential
- GaussianDropout
- GaussianNoise
- GlobalAvgPool1D
- GlobalAvgPool2D
- GlobalAvgPool3D
- GlobalMaxPool1D
- GlobalMaxPool2D
- GlobalMaxPool3D
- GRU
- GELU
- Input
- LayerNormalization
- LSTM
- MaxPool1D
- MaxPool2D
- MaxPool3D
- MultiHeadAttention
- HardSigmoid
- LeakyReLU
- Linear
- Multiply
- Permute3D
- Reshape
- RNN
- PReLU
- ReLU
- SELU
- Output Predict
- Output Train
- SeparableConv1D
- SeparableConv2D
- SimpleRNN
- SpatialDropout
- Sigmoid
- SoftMax
- SoftPlus
- SoftSign
- Split
- UpSampling1D
- UpSampling2D
- UpSampling3D
- ZeroPadding1D
- ZeroPadding2D
- ZeroPadding3D
- Swish
- TanH
- ThresholdedReLU
- Substract
- Show All Articles (63) Collapse Articles
-
-
-
-
- Exp
- Identity
- Abs
- Acos
- Acosh
- ArgMax
- ArgMin
- Asin
- Asinh
- Atan
- Atanh
- AveragePool
- Bernouilli
- BitwiseNot
- BlackmanWindow
- Cast
- Ceil
- Celu
- ConcatFromSequence
- Cos
- Cosh
- DepthToSpace
- Det
- DynamicTimeWarping
- Erf
- EyeLike
- Flatten
- Floor
- GlobalAveragePool
- GlobalLpPool
- GlobalMaxPool
- HammingWindow
- HannWindow
- HardSwish
- HardMax
- lrfft
- lsNaN
- Log
- LogSoftmax
- LpNormalization
- LpPool
- LRN
- MeanVarianceNormalization
- MicrosoftGelu
- Mish
- Multinomial
- MurmurHash3
- Neg
- NhwcMaxPool
- NonZero
- Not
- OptionalGetElement
- OptionalHasElement
- QuickGelu
- RandomNormalLike
- RandomUniformLike
- RawConstantOfShape
- Reciprocal
- ReduceSumInteger
- RegexFullMatch
- Rfft
- Round
- SampleOp
- Shape
- SequenceLength
- Shrink
- Sin
- Sign
- Sinh
- Size
- SpaceToDepth
- Sqrt
- StringNormalizer
- Tan
- TfldfVectorizer
- Tokenizer
- Transpose
- UnfoldTensor
- lslnf
- ImageDecoder
- Inverse
- Show All Articles (65) Collapse Articles
-
-
-
- Add
- AffineGrid
- And
- BiasAdd
- BiasGelu
- BiasSoftmax
- BiasSplitGelu
- BitShift
- BitwiseAnd
- BitwiseOr
- BitwiseXor
- CastLike
- CDist
- CenterCropPad
- Clip
- Col2lm
- ComplexMul
- ComplexMulConj
- Compress
- ConvInteger
- Conv
- ConvTranspose
- ConvTransposeWithDynamicPads
- CropAndResize
- CumSum
- DeformConv
- DequantizeBFP
- DequantizeLinear
- DequantizeWithOrder
- DFT
- Div
- DynamicQuantizeMatMul
- Equal
- Expand
- ExpandDims
- FastGelu
- FusedConv
- FusedGemm
- FusedMatMul
- FusedMatMulActivation
- GatedRelativePositionBias
- Gather
- GatherElements
- GatherND
- Gemm
- GemmFastGelu
- GemmFloat8
- Greater
- GreaterOrEqual
- GreedySearch
- GridSample
- GroupNorm
- InstanceNormalization
- Less
- LessOrEqual
- LongformerAttention
- MatMul
- MatMulBnb4
- MatMulFpQ4
- MatMulInteger
- MatMulInteger16
- MatMulIntergerToFloat
- MatMulNBits
- MaxPoolWithMask
- MaxRoiPool
- MaxUnPool
- MelWeightMatrix
- MicrosoftDequantizeLinear
- MicrosoftGatherND
- MicrosoftGridSample
- MicrosoftPad
- MicrosoftQLinearConv
- MicrosoftQuantizeLinear
- MicrosoftRange
- MicrosoftTrilu
- Mod
- MoE
- Mul
- MulInteger
- NegativeLogLikelihoodLoss
- NGramRepeatBlock
- NhwcConv
- NhwcFusedConv
- NonMaxSuppression
- OneHot
- Or
- PackedAttention
- PackedMultiHeadAttention
- Pad
- Pow
- QGemm
- QLinearAdd
- QLinearAveragePool
- QLinearConcat
- QLinearConv
- QLinearGlobalAveragePool
- QLinearLeakyRelu
- QLinearMatMul
- QLinearMul
- QLinearReduceMean
- QLinearSigmoid
- QLinearSoftmax
- QLinearWhere
- QMoE
- QOrderedAttention
- QOrderedGelu
- QOrderedLayerNormalization
- QOrderedLongformerAttention
- QOrderedMatMul
- QuantizeLinear
- QuantizeWithOrder
- Range
- ReduceL1
- ReduceL2
- ReduceLogSum
- ReduceLogSumExp
- ReduceMax
- ReduceMean
- ReduceMin
- ReduceProd
- ReduceSum
- ReduceSumSquare
- RelativePositionBias
- Reshape
- Resize
- RestorePadding
- ReverseSequence
- RoiAlign
- RotaryEmbedding
- ScatterElements
- ScatterND
- SequenceAt
- SequenceErase
- SequenceInsert
- Sinh
- Slice
- SparseToDenseMatMul
- SplitToSequence
- Squeeze
- STFT
- StringConcat
- Sub
- Tile
- TorchEmbedding
- TransposeMatMul
- Trilu
- Unsqueeze
- Where
- WordConvEmbedding
- Xor
- Show All Articles (134) Collapse Articles
-
- Attention
- AttnLSTM
- BatchNormalization
- BiasDropout
- BifurcationDetector
- BitmaskBiasDropout
- BitmaskDropout
- DecoderAttention
- DecoderMaskedMultiHeadAttention
- DecoderMaskedSelfAttention
- Dropout
- DynamicQuantizeLinear
- DynamicQuantizeLSTM
- EmbedLayerNormalization
- GemmaRotaryEmbedding
- GroupQueryAttention
- GRU
- LayerNormalization
- LSTM
- MicrosoftMultiHeadAttention
- QAttention
- RemovePadding
- RNN
- Sampling
- SkipGroupNorm
- SkipLayerNormalization
- SkipSimplifiedLayerNormalization
- SoftmaxCrossEntropyLoss
- SparseAttention
- TopK
- WhisperBeamSearch
- Show All Articles (15) Collapse Articles
-
-
-
-
-
-
-
-
-
-
- AdditiveAttention
- Attention
- BatchNormalization
- Bidirectional
- Conv1D
- Conv2D
- Conv1DTranspose
- Conv2DTranspose
- Conv3DTranspose
- Conv3D
- ConvLSTM1D
- ConvLSTM2D
- ConvLSTM3D
- Dense
- DepthwiseConv2D
- Embedding
- LayerNormalization
- GRU
- LSTM
- PReLU 2D
- PReLU 3D
- PReLU 4D
- PReLU 5D
- MutiHeadAttention
- SeparableConv1D
- SeparableConv2D
- MultiHeadAttention
- RNN (GRU)
- RNN (LSTM)
- RNN (SimpleRNN)
- SimpleRNN
- 1D
- 2D
- 3D
- 4D
- 5D
- 6D
- Scalar
- Show All Articles (22) Collapse Articles
-
- AdditiveAttention
- Attention
- BatchNormalization
- Conv1D
- Conv2D
- Conv1DTranspose
- Conv2DTranspose
- Bidirectional
- Conv3D
- ConvLSTM1D
- ConvLSTM2D
- ConvLSTM3D
- Conv3DTranspose
- DepthwiseConv2D
- Dense
- Embedding
- LayerNormalization
- GRU
- PReLU 2D
- PReLU 3D
- PReLU 4D
- MultiHeadAttention
- LSTM
- PReLU 5D
- SeparableConv1D
- SeparableConv2D
- SimpleRNN
- RNN (GRU)
- RNN (LSTM)
- RNN (SimpleRNN)
- 1D
- 2D
- 3D
- 4D
- 5D
- 6D
- Scalar
- Show All Articles (21) Collapse Articles
-
-
- AdditiveAttention
- Attention
- BatchNormalization
- Bidirectional
- Conv1D
- Conv2D
- Conv3D
- Conv1DTranspose
- Conv2DTranspose
- Conv3DTranspose
- ConvLSTM1D
- ConvLSTM2D
- ConvLSTM3D
- Dense
- DepthwiseConv2D
- Embedding
- GRU
- LayerNormalization
- LSTM
- MultiHeadAttention
- PReLU 2D
- PReLU 3D
- PReLU 4D
- PReLU 5D
- Resume
- SeparableConv1D
- SeparableConv2D
- SimpleRNN
- Show All Articles (12) Collapse Articles
-
-
- Dense
- Embedding
- AdditiveAttention
- Attention
- MultiHeadAttention
- Conv1D
- Conv2D
- Conv3D
- ConvLSTM1D
- ConvLSTM2D
- ConvLSTM3D
- Conv1DTranspose
- Conv2DTranspose
- Conv3DTranspose
- DepthwiseConv2D
- SeparableConv1D
- SeparableConv2D
- BatchNormalization
- LayerNormalization
- PReLU 2D
- PReLU 3D
- PReLU 4D
- PReLU 5D
- Bidirectional
- GRU
- LSTM
- RNN (GRU)
- RNN (LSTM)
- RNN (SimpleRNN)
- SimpleRNN
- PReLU 4D
- Show All Articles (15) Collapse Articles
-
- Dense
- Embedding
- AdditiveAttention
- Attention
- MultiHeadAttention
- Conv1D
- Conv2D
- Conv3D
- ConvLSTM1D
- ConvLSTM2D
- ConvLSTM3D
- Conv1DTranspose
- Conv2DTranspose
- Conv3DTranspose
- DepthwiseConv2D
- SeparableConv1D
- SeparableConv2D
- BatchNormalization
- LayerNormalization
- PReLU 2D
- PReLU 3D
- PReLU 4D
- PReLU 5D
- Bidirectional
- GRU
- LSTM
- RNN (GRU)
- RNN (LSTM)
- RNN (SimpleRNN)
- SimpleRNN
- Show All Articles (14) Collapse Articles
-
-
- Accuracy
- BinaryAccuracy
- BinaryCrossentropy
- BinaryIoU
- CategoricalAccuracy
- CategoricalCrossentropy
- CategoricalHinge
- CosineSimilarity
- FalseNegatives
- FalsePositives
- Hinge
- Huber
- IoU
- KLDivergence
- LogCoshError
- Mean
- MeanAbsoluteError
- MeanAbsolutePercentageError
- MeanIoU
- MeanRelativeError
- MeanSquaredError
- MeanSquaredLogarithmicError
- MeanTensor
- OneHotIoU
- OneHotMeanIoU
- Poisson
- Precision
- PrecisionAtRecall
- Recall
- RecallAtPrecision
- RootMeanSquaredError
- SensitivityAtSpecificity
- SparseCategoricalAccuracy
- SparseCategoricalCrossentropy
- SparseTopKCategoricalAccuracy
- Specificity
- SpecificityAtSensitivity
- SquaredHinge
- Sum
- TopKCategoricalAccuracy
- TrueNegatives
- TruePositives
- Resume
- Show All Articles (27) Collapse Articles
-
-
- Dense
- Embedding
- AdditiveAttention
- Attention
- MultiHeadAttention
- Conv1D
- Conv2D
- Conv3D
- ConvLSTM1D
- ConvLSTM2D
- ConvLSTM3D
- Conv1DTranspose
- Conv2DTranspose
- Conv3DTranspose
- DepthwiseConv2D
- SeparableConv1D
- SeparableConv2D
- BatchNormalization
- LayerNormalization
- PReLU 2D
- PReLU 3D
- PReLU 4D
- PReLU 5D
- Bidirectional
- GRU
- LSTM
- RNN (GRU)
- RNN (LSTM)
- RNN (SimpleRNN)
- SimpleRNN
- Show All Articles (14) Collapse Articles
-
- Dense
- Embedding
- AdditiveAttention
- Attention
- MultiHeadAttention
- Conv1D
- Conv2D
- Conv3D
- ConvLSTM1D
- ConvLSTM2D
- ConvLSTM3D
- Conv1DTranspose
- Conv2DTranspose
- Conv3DTranspose
- DepthwiseConv2D
- SeparableConv1D
- SeparableConv2D
- LayerNormalization
- PReLU 2D
- PReLU 3D
- PReLU 4D
- PReLU 5D
- Bidirectional
- GRU
- LSTM
- RNN (GRU)
- RNN (LSTM)
- RNN (SimpleRNN)
- SimpleRNN
- BatchNormalization
- Show All Articles (14) Collapse Articles
-
-
-
Computer Vision Toolkit
-
CUDA Toolkit
-
- Resume
- Array size
- Index Array
- Replace Subset
- Insert Into Array
- Delete From Array
- Initialize Array
- Build Array
- Concatenate Array
- Array Subset
- Min & Max
- Reshape Array
- Short Array
- Reverse 1D array
- Shuffle array
- Search In Array
- Split 1D Array
- Split 2D Array
- Rotate 1D Array
- Increment Array Element
- Decrement Array Element
- Interpolate 1D Array
- Threshold 1D Array
- Interleave 1D Array
- Decimate 1D Array
- Transpose Array
- Remove Duplicate From 1D Array
- Show All Articles (11) Collapse Articles
-
-
- Resume
- Add
- Substract
- Multiply
- Divide
- Quotient & Remainder
- Increment
- Decrement
- Add Array Element
- Multiply Array Element
- Absolute
- Round To Nearest
- Round Toward -Infinity
- Round Toward +Infinity
- Scale By Power Of Two
- Square Root
- Square
- Negate
- Reciprocal
- Sign
- Show All Articles (4) Collapse Articles
Loop
Description
Generic Looping construct.
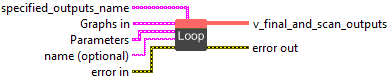
This loop has multiple termination conditions :
- Trip count. Iteration count specified at runtime. Set by specifying the input M. Optional. Set to empty string to omit. Note that a static trip count (specified at graph construction time) can be specified by passing in a constant node for input M.
- Loop termination condition. This is an input to the op that determines whether to run the first iteration and also a loop-carried dependency for the body graph. The body graph must yield a value for the condition variable, whether this input is provided or not.
Input parameters
![]() specified_outputs_name : array, this parameter lets you manually assign custom names to the output tensors of a node.
specified_outputs_name : array, this parameter lets you manually assign custom names to the output tensors of a node.
![]() Graphs in : cluster, ONNX model architecture.
Graphs in : cluster, ONNX model architecture.
![]() M (optional, heterogeneous) – I : object, a maximum trip-count for the loop specified at runtime. Optional. Pass empty string to skip.
M (optional, heterogeneous) – I : object, a maximum trip-count for the loop specified at runtime. Optional. Pass empty string to skip.![]() cond (optional, heterogeneous) – B : object, a boolean termination condition. Optional. Pass empty string to skip.
cond (optional, heterogeneous) – B : object, a boolean termination condition. Optional. Pass empty string to skip.![]() v_initial (variadic) – V : array, the initial values of any loop-carried dependencies (values that change across loop iterations).
v_initial (variadic) – V : array, the initial values of any loop-carried dependencies (values that change across loop iterations).

![]() Parameters : cluster,
Parameters : cluster,
![]() body : object, the graph run each iteration. It has 2+N inputs: (iteration_num, condition, loop carried dependencies…). It has 1+N+K outputs: (condition, loop carried dependencies…, scan_outputs…). Each scan_output is created by concatenating the value of the specified output value at the end of each iteration of the loop. It is an error if the dimensions or data type of these scan_outputs change across loop iterations.
body : object, the graph run each iteration. It has 2+N inputs: (iteration_num, condition, loop carried dependencies…). It has 1+N+K outputs: (condition, loop carried dependencies…, scan_outputs…). Each scan_output is created by concatenating the value of the specified output value at the end of each iteration of the loop. It is an error if the dimensions or data type of these scan_outputs change across loop iterations.![]() training? : boolean, whether the layer is in training mode (can store data for backward).
training? : boolean, whether the layer is in training mode (can store data for backward).
Default value “True”.![]() lda coeff : float, defines the coefficient by which the loss derivative will be multiplied before being sent to the previous layer (since during the backward run we go backwards).
lda coeff : float, defines the coefficient by which the loss derivative will be multiplied before being sent to the previous layer (since during the backward run we go backwards).
Default value “1”.
![]() name (optional) : string, name of the node.
name (optional) : string, name of the node.

Output parameters
![]() v_final_and_scan_outputs (variadic) – V : array, final N loop carried dependency values then K scan_outputs. Scan outputs must be Tensors.
v_final_and_scan_outputs (variadic) – V : array, final N loop carried dependency values then K scan_outputs. Scan outputs must be Tensors.
Type Constraints
V in (optional(seq(tensor(bfloat16))), optional(seq(tensor(bool))), optional(seq(tensor(complex128))), optional(seq(tensor(complex64))), optional(seq(tensor(double))), optional(seq(tensor(float))), optional(seq(tensor(float16))), optional(seq(tensor(int16))), optional(seq(tensor(int32))), optional(seq(tensor(int64))), optional(seq(tensor(int8))), optional(seq(tensor(string))), optional(seq(tensor(uint16))), optional(seq(tensor(uint32))), optional(seq(tensor(uint64))), optional(seq(tensor(uint8))), optional(tensor(bfloat16)), optional(tensor(bool)), optional(tensor(complex128)), optional(tensor(complex64)), optional(tensor(double)), optional(tensor(float)), optional(tensor(float16)), optional(tensor(float8e4m3fn)), optional(tensor(float8e4m3fnuz)), optional(tensor(float8e5m2)), optional(tensor(float8e5m2fnuz)), optional(tensor(int16)), optional(tensor(int32)), optional(tensor(int64)), optional(tensor(int8)), optional(tensor(string)), optional(tensor(uint16)), optional(tensor(uint32)), optional(tensor(uint64)), optional(tensor(uint8)), seq(tensor(bfloat16)), seq(tensor(bool)), seq(tensor(complex128)), seq(tensor(complex64)), seq(tensor(double)), seq(tensor(float)), seq(tensor(float16)), seq(tensor(float8e4m3fn)), seq(tensor(float8e4m3fnuz)), seq(tensor(float8e5m2)), seq(tensor(float8e5m2fnuz)), seq(tensor(int16)), seq(tensor(int32)), seq(tensor(int64)), seq(tensor(int8)), seq(tensor(string)), seq(tensor(uint16)), seq(tensor(uint32)), seq(tensor(uint64)), seq(tensor(uint8)), tensor(bfloat16), tensor(bool), tensor(complex128), tensor(complex64), tensor(double), tensor(float), tensor(float16), tensor(float8e4m3fn), tensor(float8e4m3fnuz), tensor(float8e5m2), tensor(float8e5m2fnuz), tensor(int16), tensor(int32), tensor(int64), tensor(int8), tensor(string), tensor(uint16), tensor(uint32), tensor(uint64), tensor(uint8)) : All Tensor, Sequence(Tensor), Optional(Tensor), and Optional(Sequence(Tensor)) types up to IRv9.
I in (tensor(int64)) : tensor of int64, which should be a scalar.
B in (tensor(bool)) : tensor of bool, which should be a scalar.