
-
SOTA
-
Accelerator Toolkit
-
Deep Learning Toolkit
-
-
- Resume
- Add
- AlphaDropout
- AdditiveAttention
- Attention
- Average
- AvgPool1D
- AvgPool2D
- AvgPool3D
- BatchNormalization
- Bidirectional
- Concatenate
- Conv1D
- Conv1DTranspose
- Conv2D
- Conv2DTranspose
- Conv3D
- Conv3DTranspose
- ConvLSTM1D
- ConvLSTM2D
- ConvLSTM3D
- Dense
- Cropping1D
- Cropping2D
- Cropping3D
- DepthwiseConv2D
- Dropout
- Embedding
- Flatten
- ELU
- Exponential
- GaussianDropout
- GaussianNoise
- GlobalAvgPool1D
- GlobalAvgPool2D
- GlobalAvgPool3D
- GlobalMaxPool1D
- GlobalMaxPool2D
- GlobalMaxPool3D
- GRU
- GELU
- Input
- LayerNormalization
- LSTM
- MaxPool1D
- MaxPool2D
- MaxPool3D
- MultiHeadAttention
- HardSigmoid
- LeakyReLU
- Linear
- Multiply
- Permute3D
- Reshape
- RNN
- PReLU
- ReLU
- SELU
- Output Predict
- Output Train
- SeparableConv1D
- SeparableConv2D
- SimpleRNN
- SpatialDropout
- Sigmoid
- SoftMax
- SoftPlus
- SoftSign
- Split
- UpSampling1D
- UpSampling2D
- UpSampling3D
- ZeroPadding1D
- ZeroPadding2D
- ZeroPadding3D
- Swish
- TanH
- ThresholdedReLU
- Substract
- Show All Articles (63) Collapse Articles
-
-
-
-
- Exp
- Identity
- Abs
- Acos
- Acosh
- ArgMax
- ArgMin
- Asin
- Asinh
- Atan
- Atanh
- AveragePool
- Bernouilli
- BitwiseNot
- BlackmanWindow
- Cast
- Ceil
- Celu
- ConcatFromSequence
- Cos
- Cosh
- DepthToSpace
- Det
- DynamicTimeWarping
- Erf
- EyeLike
- Flatten
- Floor
- GlobalAveragePool
- GlobalLpPool
- GlobalMaxPool
- HammingWindow
- HannWindow
- HardSwish
- HardMax
- lrfft
- lsNaN
- Log
- LogSoftmax
- LpNormalization
- LpPool
- LRN
- MeanVarianceNormalization
- MicrosoftGelu
- Mish
- Multinomial
- MurmurHash3
- Neg
- NhwcMaxPool
- NonZero
- Not
- OptionalGetElement
- OptionalHasElement
- QuickGelu
- RandomNormalLike
- RandomUniformLike
- RawConstantOfShape
- Reciprocal
- ReduceSumInteger
- RegexFullMatch
- Rfft
- Round
- SampleOp
- Shape
- SequenceLength
- Shrink
- Sin
- Sign
- Sinh
- Size
- SpaceToDepth
- Sqrt
- StringNormalizer
- Tan
- TfldfVectorizer
- Tokenizer
- Transpose
- UnfoldTensor
- lslnf
- ImageDecoder
- Inverse
- Show All Articles (65) Collapse Articles
-
-
-
- Add
- AffineGrid
- And
- BiasAdd
- BiasGelu
- BiasSoftmax
- BiasSplitGelu
- BitShift
- BitwiseAnd
- BitwiseOr
- BitwiseXor
- CastLike
- CDist
- CenterCropPad
- Clip
- Col2lm
- ComplexMul
- ComplexMulConj
- Compress
- ConvInteger
- Conv
- ConvTranspose
- ConvTransposeWithDynamicPads
- CropAndResize
- CumSum
- DeformConv
- DequantizeBFP
- DequantizeLinear
- DequantizeWithOrder
- DFT
- Div
- DynamicQuantizeMatMul
- Equal
- Expand
- ExpandDims
- FastGelu
- FusedConv
- FusedGemm
- FusedMatMul
- FusedMatMulActivation
- GatedRelativePositionBias
- Gather
- GatherElements
- GatherND
- Gemm
- GemmFastGelu
- GemmFloat8
- Greater
- GreaterOrEqual
- GreedySearch
- GridSample
- GroupNorm
- InstanceNormalization
- Less
- LessOrEqual
- LongformerAttention
- MatMul
- MatMulBnb4
- MatMulFpQ4
- MatMulInteger
- MatMulInteger16
- MatMulIntergerToFloat
- MatMulNBits
- MaxPoolWithMask
- MaxRoiPool
- MaxUnPool
- MelWeightMatrix
- MicrosoftDequantizeLinear
- MicrosoftGatherND
- MicrosoftGridSample
- MicrosoftPad
- MicrosoftQLinearConv
- MicrosoftQuantizeLinear
- MicrosoftRange
- MicrosoftTrilu
- Mod
- MoE
- Mul
- MulInteger
- NegativeLogLikelihoodLoss
- NGramRepeatBlock
- NhwcConv
- NhwcFusedConv
- NonMaxSuppression
- OneHot
- Or
- PackedAttention
- PackedMultiHeadAttention
- Pad
- Pow
- QGemm
- QLinearAdd
- QLinearAveragePool
- QLinearConcat
- QLinearConv
- QLinearGlobalAveragePool
- QLinearLeakyRelu
- QLinearMatMul
- QLinearMul
- QLinearReduceMean
- QLinearSigmoid
- QLinearSoftmax
- QLinearWhere
- QMoE
- QOrderedAttention
- QOrderedGelu
- QOrderedLayerNormalization
- QOrderedLongformerAttention
- QOrderedMatMul
- QuantizeLinear
- QuantizeWithOrder
- Range
- ReduceL1
- ReduceL2
- ReduceLogSum
- ReduceLogSumExp
- ReduceMax
- ReduceMean
- ReduceMin
- ReduceProd
- ReduceSum
- ReduceSumSquare
- RelativePositionBias
- Reshape
- Resize
- RestorePadding
- ReverseSequence
- RoiAlign
- RotaryEmbedding
- ScatterElements
- ScatterND
- SequenceAt
- SequenceErase
- SequenceInsert
- Sinh
- Slice
- SparseToDenseMatMul
- SplitToSequence
- Squeeze
- STFT
- StringConcat
- Sub
- Tile
- TorchEmbedding
- TransposeMatMul
- Trilu
- Unsqueeze
- Where
- WordConvEmbedding
- Xor
- Show All Articles (134) Collapse Articles
-
- Attention
- AttnLSTM
- BatchNormalization
- BiasDropout
- BifurcationDetector
- BitmaskBiasDropout
- BitmaskDropout
- DecoderAttention
- DecoderMaskedMultiHeadAttention
- DecoderMaskedSelfAttention
- Dropout
- DynamicQuantizeLinear
- DynamicQuantizeLSTM
- EmbedLayerNormalization
- GemmaRotaryEmbedding
- GroupQueryAttention
- GRU
- LayerNormalization
- LSTM
- MicrosoftMultiHeadAttention
- QAttention
- RemovePadding
- RNN
- Sampling
- SkipGroupNorm
- SkipLayerNormalization
- SkipSimplifiedLayerNormalization
- SoftmaxCrossEntropyLoss
- SparseAttention
- TopK
- WhisperBeamSearch
- Show All Articles (15) Collapse Articles
-
-
-
-
-
-
-
-
-
-
- AdditiveAttention
- Attention
- BatchNormalization
- Bidirectional
- Conv1D
- Conv2D
- Conv1DTranspose
- Conv2DTranspose
- Conv3DTranspose
- Conv3D
- ConvLSTM1D
- ConvLSTM2D
- ConvLSTM3D
- Dense
- DepthwiseConv2D
- Embedding
- LayerNormalization
- GRU
- LSTM
- PReLU 2D
- PReLU 3D
- PReLU 4D
- PReLU 5D
- MutiHeadAttention
- SeparableConv1D
- SeparableConv2D
- MultiHeadAttention
- RNN (GRU)
- RNN (LSTM)
- RNN (SimpleRNN)
- SimpleRNN
- 1D
- 2D
- 3D
- 4D
- 5D
- 6D
- Scalar
- Show All Articles (22) Collapse Articles
-
- AdditiveAttention
- Attention
- BatchNormalization
- Conv1D
- Conv2D
- Conv1DTranspose
- Conv2DTranspose
- Bidirectional
- Conv3D
- ConvLSTM1D
- ConvLSTM2D
- ConvLSTM3D
- Conv3DTranspose
- DepthwiseConv2D
- Dense
- Embedding
- LayerNormalization
- GRU
- PReLU 2D
- PReLU 3D
- PReLU 4D
- MultiHeadAttention
- LSTM
- PReLU 5D
- SeparableConv1D
- SeparableConv2D
- SimpleRNN
- RNN (GRU)
- RNN (LSTM)
- RNN (SimpleRNN)
- 1D
- 2D
- 3D
- 4D
- 5D
- 6D
- Scalar
- Show All Articles (21) Collapse Articles
-
-
- AdditiveAttention
- Attention
- BatchNormalization
- Bidirectional
- Conv1D
- Conv2D
- Conv3D
- Conv1DTranspose
- Conv2DTranspose
- Conv3DTranspose
- ConvLSTM1D
- ConvLSTM2D
- ConvLSTM3D
- Dense
- DepthwiseConv2D
- Embedding
- GRU
- LayerNormalization
- LSTM
- MultiHeadAttention
- PReLU 2D
- PReLU 3D
- PReLU 4D
- PReLU 5D
- Resume
- SeparableConv1D
- SeparableConv2D
- SimpleRNN
- Show All Articles (12) Collapse Articles
-
-
- Dense
- Embedding
- AdditiveAttention
- Attention
- MultiHeadAttention
- Conv1D
- Conv2D
- Conv3D
- ConvLSTM1D
- ConvLSTM2D
- ConvLSTM3D
- Conv1DTranspose
- Conv2DTranspose
- Conv3DTranspose
- DepthwiseConv2D
- SeparableConv1D
- SeparableConv2D
- BatchNormalization
- LayerNormalization
- PReLU 2D
- PReLU 3D
- PReLU 4D
- PReLU 5D
- Bidirectional
- GRU
- LSTM
- RNN (GRU)
- RNN (LSTM)
- RNN (SimpleRNN)
- SimpleRNN
- PReLU 4D
- Show All Articles (15) Collapse Articles
-
- Dense
- Embedding
- AdditiveAttention
- Attention
- MultiHeadAttention
- Conv1D
- Conv2D
- Conv3D
- ConvLSTM1D
- ConvLSTM2D
- ConvLSTM3D
- Conv1DTranspose
- Conv2DTranspose
- Conv3DTranspose
- DepthwiseConv2D
- SeparableConv1D
- SeparableConv2D
- BatchNormalization
- LayerNormalization
- PReLU 2D
- PReLU 3D
- PReLU 4D
- PReLU 5D
- Bidirectional
- GRU
- LSTM
- RNN (GRU)
- RNN (LSTM)
- RNN (SimpleRNN)
- SimpleRNN
- Show All Articles (14) Collapse Articles
-
-
- Accuracy
- BinaryAccuracy
- BinaryCrossentropy
- BinaryIoU
- CategoricalAccuracy
- CategoricalCrossentropy
- CategoricalHinge
- CosineSimilarity
- FalseNegatives
- FalsePositives
- Hinge
- Huber
- IoU
- KLDivergence
- LogCoshError
- Mean
- MeanAbsoluteError
- MeanAbsolutePercentageError
- MeanIoU
- MeanRelativeError
- MeanSquaredError
- MeanSquaredLogarithmicError
- MeanTensor
- OneHotIoU
- OneHotMeanIoU
- Poisson
- Precision
- PrecisionAtRecall
- Recall
- RecallAtPrecision
- RootMeanSquaredError
- SensitivityAtSpecificity
- SparseCategoricalAccuracy
- SparseCategoricalCrossentropy
- SparseTopKCategoricalAccuracy
- Specificity
- SpecificityAtSensitivity
- SquaredHinge
- Sum
- TopKCategoricalAccuracy
- TrueNegatives
- TruePositives
- Resume
- Show All Articles (27) Collapse Articles
-
-
- Dense
- Embedding
- AdditiveAttention
- Attention
- MultiHeadAttention
- Conv1D
- Conv2D
- Conv3D
- ConvLSTM1D
- ConvLSTM2D
- ConvLSTM3D
- Conv1DTranspose
- Conv2DTranspose
- Conv3DTranspose
- DepthwiseConv2D
- SeparableConv1D
- SeparableConv2D
- BatchNormalization
- LayerNormalization
- PReLU 2D
- PReLU 3D
- PReLU 4D
- PReLU 5D
- Bidirectional
- GRU
- LSTM
- RNN (GRU)
- RNN (LSTM)
- RNN (SimpleRNN)
- SimpleRNN
- Show All Articles (14) Collapse Articles
-
- Dense
- Embedding
- AdditiveAttention
- Attention
- MultiHeadAttention
- Conv1D
- Conv2D
- Conv3D
- ConvLSTM1D
- ConvLSTM2D
- ConvLSTM3D
- Conv1DTranspose
- Conv2DTranspose
- Conv3DTranspose
- DepthwiseConv2D
- SeparableConv1D
- SeparableConv2D
- LayerNormalization
- PReLU 2D
- PReLU 3D
- PReLU 4D
- PReLU 5D
- Bidirectional
- GRU
- LSTM
- RNN (GRU)
- RNN (LSTM)
- RNN (SimpleRNN)
- SimpleRNN
- BatchNormalization
- Show All Articles (14) Collapse Articles
-
-
-
Computer Vision Toolkit
-
CUDA Toolkit
-
- Resume
- Array size
- Index Array
- Replace Subset
- Insert Into Array
- Delete From Array
- Initialize Array
- Build Array
- Concatenate Array
- Array Subset
- Min & Max
- Reshape Array
- Short Array
- Reverse 1D array
- Shuffle array
- Search In Array
- Split 1D Array
- Split 2D Array
- Rotate 1D Array
- Increment Array Element
- Decrement Array Element
- Interpolate 1D Array
- Threshold 1D Array
- Interleave 1D Array
- Decimate 1D Array
- Transpose Array
- Remove Duplicate From 1D Array
- Show All Articles (11) Collapse Articles
-
-
- Resume
- Add
- Substract
- Multiply
- Divide
- Quotient & Remainder
- Increment
- Decrement
- Add Array Element
- Multiply Array Element
- Absolute
- Round To Nearest
- Round Toward -Infinity
- Round Toward +Infinity
- Scale By Power Of Two
- Square Root
- Square
- Negate
- Reciprocal
- Sign
- Show All Articles (4) Collapse Articles
CUDA
Description
Create Cuda Session with its Session Options on the stored local Env. Type : polymorphic.
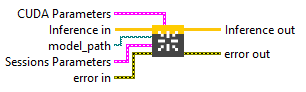
Input parameters
![]() Inference in : object, inference session.
Inference in : object, inference session.![]() model_path : path, is the path to the model file.
model_path : path, is the path to the model file.
![]() Sessions Parameters : cluster
Sessions Parameters : cluster
![]() intra_op_num_threads : integer, number of threads used within each operator to parallelize computations. If the value is 0, ONNX Runtime automatically uses the number of physical CPU cores.
intra_op_num_threads : integer, number of threads used within each operator to parallelize computations. If the value is 0, ONNX Runtime automatically uses the number of physical CPU cores.![]() inter_op_num_threads : integer, number of threads used between operators, to execute multiple graph nodes in parallel. If set to 0, this parameter is ignored when
inter_op_num_threads : integer, number of threads used between operators, to execute multiple graph nodes in parallel. If set to 0, this parameter is ignored when execution_mode is ORT_SEQUENTIAL. In ORT_PARALLEL mode, 0 means ORT automatically selects a suitable number of threads (usually equal to the number of cores).![]() execution_mode : enum, controls whether the graph executes nodes one after another or allows parallel execution when possible.
execution_mode : enum, controls whether the graph executes nodes one after another or allows parallel execution when possible.ORT_SEQUENTIAL runs nodes in order, ORT_PARALLEL runs them concurrently.![]() deterministic_compute : boolean, forces deterministic execution, meaning results will always be identical for the same inputs.
deterministic_compute : boolean, forces deterministic execution, meaning results will always be identical for the same inputs.![]() graph_optimization_level : enum, defines how much ONNX Runtime optimizes the computation graph before running the model.
graph_optimization_level : enum, defines how much ONNX Runtime optimizes the computation graph before running the model.![]() optimized_model_file_path : path, file path to save the optimized model after graph analysis.
optimized_model_file_path : path, file path to save the optimized model after graph analysis.![]() profiling output dir : path, specifies the directory where ONNX Runtime will save profiling output files. If you set this parameter to a valid (non-empty) path, profiling is automatically enabled. However, if the path is empty, profiling will not be activated.
profiling output dir : path, specifies the directory where ONNX Runtime will save profiling output files. If you set this parameter to a valid (non-empty) path, profiling is automatically enabled. However, if the path is empty, profiling will not be activated.

![]() CUDA Parameters : cluster
CUDA Parameters : cluster
![]() Device & Stream : cluster,
Device & Stream : cluster,
![]() Device Index : integer, ID of the CUDA device used for inference (default = 0).
Device Index : integer, ID of the CUDA device used for inference (default = 0).![]() Use Custom Compute Stream? : boolean, if true, the model will run using a user-provided CUDA compute stream.
Use Custom Compute Stream? : boolean, if true, the model will run using a user-provided CUDA compute stream.![]() Custom Compute Stream (Pointer) : integer, pointer or reference to the user CUDA stream.
Custom Compute Stream (Pointer) : integer, pointer or reference to the user CUDA stream.![]() Copy Using Default Stream? : boolean, if true, host-device transfers are executed in the default CUDA stream.
Copy Using Default Stream? : boolean, if true, host-device transfers are executed in the default CUDA stream.
![]() Memory Management : cluster,
Memory Management : cluster,
![]() GPU Memory Limit (Bytes) : integer, maximum GPU memory the CUDA EP can allocate (default = unlimited).
GPU Memory Limit (Bytes) : integer, maximum GPU memory the CUDA EP can allocate (default = unlimited).![]() Arena Extension Strategy : enum, defines how the GPU memory arena grows : “NextPowerOfTwo” (default) or “SameAsRequested”.
Arena Extension Strategy : enum, defines how the GPU memory arena grows : “NextPowerOfTwo” (default) or “SameAsRequested”.![]() Default Memory Arena Config : integer, optional pointer to a custom OrtArenaCfg; overrides other memory parameters.
Default Memory Arena Config : integer, optional pointer to a custom OrtArenaCfg; overrides other memory parameters.
![]() CuDNN & Kernel Optimization : cluster,
CuDNN & Kernel Optimization : cluster,
![]() cuDNN Convolution Algorithm Search : enum, strategy for cuDNN convolution kernel selection : Exhaustive, Heuristic, or Default.
cuDNN Convolution Algorithm Search : enum, strategy for cuDNN convolution kernel selection : Exhaustive, Heuristic, or Default.![]() Use Max Workspace for cuDNN? : boolean, if true, cuDNN may use the largest available workspace for best performance.
Use Max Workspace for cuDNN? : boolean, if true, cuDNN may use the largest available workspace for best performance.![]() Pad Conv1D Inputs to NC1D? : boolean, automatically pads 1D convolution inputs to [N,C,1,D] or [N,C,D,1] for compatibility.
Pad Conv1D Inputs to NC1D? : boolean, automatically pads 1D convolution inputs to [N,C,1,D] or [N,C,D,1] for compatibility.![]() Fuse Convolution + Bias? : boolean, enables cuDNN Frontend fusion of convolution and bias layers (JIT-compiled kernels).
Fuse Convolution + Bias? : boolean, enables cuDNN Frontend fusion of convolution and bias layers (JIT-compiled kernels).![]() Scaled Dot-Product Attention Kernel Option : boolean, selects the implementation of the SDPA kernel (0 = default).
Scaled Dot-Product Attention Kernel Option : boolean, selects the implementation of the SDPA kernel (0 = default).![]() Enable Strict SkipLayerNorm Mode? : boolean, forces LayerNormalization kernel instead of SkipLayerNorm for higher accuracy at lower speed.
Enable Strict SkipLayerNorm Mode? : boolean, forces LayerNormalization kernel instead of SkipLayerNorm for higher accuracy at lower speed.
![]() Execution & Precision Controls : cluster,
Execution & Precision Controls : cluster,
![]() Enable CUDA Graph Execution? : boolean, captures model execution as a CUDA Graph for reduced launch overhead (requires static shapes).
Enable CUDA Graph Execution? : boolean, captures model execution as a CUDA Graph for reduced launch overhead (requires static shapes).![]() Use EP-Level Unified Stream? : boolean, runs all CUDA operations through one unified execution stream at the provider level.
Use EP-Level Unified Stream? : boolean, runs all CUDA operations through one unified execution stream at the provider level.![]() Prefer NHWC Tensor Layout? : boolean, uses NHWC (channels-last) tensor format where supported for better memory access.
Prefer NHWC Tensor Layout? : boolean, uses NHWC (channels-last) tensor format where supported for better memory access.![]() Use TensorFloat-32 (TF32)? : boolean, enables TensorFloat-32 tensor cores (default = true) for faster matrix math with minimal precision loss.
Use TensorFloat-32 (TF32)? : boolean, enables TensorFloat-32 tensor cores (default = true) for faster matrix math with minimal precision loss.
![]() Tunable Operator System : cluster,
Tunable Operator System : cluster,
![]() Enable Tunable Operators? : boolean, activates runtime operator tuning for optimal kernel selection.
Enable Tunable Operators? : boolean, activates runtime operator tuning for optimal kernel selection.![]() Enable Tuning Mode for Tunable Operators? : boolean, allows benchmarking multiple kernel variants to select the fastest one.
Enable Tuning Mode for Tunable Operators? : boolean, allows benchmarking multiple kernel variants to select the fastest one.![]() Max Tuning Duration (ms) : integer, maximum duration (in milliseconds) for kernel tuning before fallback to default.
Max Tuning Duration (ms) : integer, maximum duration (in milliseconds) for kernel tuning before fallback to default.

Output parameters
![]() Inference out : object, inference session.
Inference out : object, inference session.
Example
All these exemples are snippets PNG, you can drop these Snippet onto the block diagram and get the depicted code added to your VI (Do not forget to install Accelerator library to run it).