
-
SOTA
-
Accelerator Toolkit
-
Deep Learning Toolkit
-
-
- Resume
- Add
- AlphaDropout
- AdditiveAttention
- Attention
- Average
- AvgPool1D
- AvgPool2D
- AvgPool3D
- BatchNormalization
- Bidirectional
- Concatenate
- Conv1D
- Conv1DTranspose
- Conv2D
- Conv2DTranspose
- Conv3D
- Conv3DTranspose
- ConvLSTM1D
- ConvLSTM2D
- ConvLSTM3D
- Dense
- Cropping1D
- Cropping2D
- Cropping3D
- DepthwiseConv2D
- Dropout
- Embedding
- Flatten
- ELU
- Exponential
- GaussianDropout
- GaussianNoise
- GlobalAvgPool1D
- GlobalAvgPool2D
- GlobalAvgPool3D
- GlobalMaxPool1D
- GlobalMaxPool2D
- GlobalMaxPool3D
- GRU
- GELU
- Input
- LayerNormalization
- LSTM
- MaxPool1D
- MaxPool2D
- MaxPool3D
- MultiHeadAttention
- HardSigmoid
- LeakyReLU
- Linear
- Multiply
- Permute3D
- Reshape
- RNN
- PReLU
- ReLU
- SELU
- Output Predict
- Output Train
- SeparableConv1D
- SeparableConv2D
- SimpleRNN
- SpatialDropout
- Sigmoid
- SoftMax
- SoftPlus
- SoftSign
- Split
- UpSampling1D
- UpSampling2D
- UpSampling3D
- ZeroPadding1D
- ZeroPadding2D
- ZeroPadding3D
- Swish
- TanH
- ThresholdedReLU
- Substract
- Show All Articles (63) Collapse Articles
-
-
-
-
- Exp
- Identity
- Abs
- Acos
- Acosh
- ArgMax
- ArgMin
- Asin
- Asinh
- Atan
- Atanh
- AveragePool
- Bernouilli
- BitwiseNot
- BlackmanWindow
- Cast
- Ceil
- Celu
- ConcatFromSequence
- Cos
- Cosh
- DepthToSpace
- Det
- DynamicTimeWarping
- Erf
- EyeLike
- Flatten
- Floor
- GlobalAveragePool
- GlobalLpPool
- GlobalMaxPool
- HammingWindow
- HannWindow
- HardSwish
- HardMax
- lrfft
- lsNaN
- Log
- LogSoftmax
- LpNormalization
- LpPool
- LRN
- MeanVarianceNormalization
- MicrosoftGelu
- Mish
- Multinomial
- MurmurHash3
- Neg
- NhwcMaxPool
- NonZero
- Not
- OptionalGetElement
- OptionalHasElement
- QuickGelu
- RandomNormalLike
- RandomUniformLike
- RawConstantOfShape
- Reciprocal
- ReduceSumInteger
- RegexFullMatch
- Rfft
- Round
- SampleOp
- Shape
- SequenceLength
- Shrink
- Sin
- Sign
- Sinh
- Size
- SpaceToDepth
- Sqrt
- StringNormalizer
- Tan
- TfldfVectorizer
- Tokenizer
- Transpose
- UnfoldTensor
- lslnf
- ImageDecoder
- Inverse
- Show All Articles (65) Collapse Articles
-
-
-
- Add
- AffineGrid
- And
- BiasAdd
- BiasGelu
- BiasSoftmax
- BiasSplitGelu
- BitShift
- BitwiseAnd
- BitwiseOr
- BitwiseXor
- CastLike
- CDist
- CenterCropPad
- Clip
- Col2lm
- ComplexMul
- ComplexMulConj
- Compress
- ConvInteger
- Conv
- ConvTranspose
- ConvTransposeWithDynamicPads
- CropAndResize
- CumSum
- DeformConv
- DequantizeBFP
- DequantizeLinear
- DequantizeWithOrder
- DFT
- Div
- DynamicQuantizeMatMul
- Equal
- Expand
- ExpandDims
- FastGelu
- FusedConv
- FusedGemm
- FusedMatMul
- FusedMatMulActivation
- GatedRelativePositionBias
- Gather
- GatherElements
- GatherND
- Gemm
- GemmFastGelu
- GemmFloat8
- Greater
- GreaterOrEqual
- GreedySearch
- GridSample
- GroupNorm
- InstanceNormalization
- Less
- LessOrEqual
- LongformerAttention
- MatMul
- MatMulBnb4
- MatMulFpQ4
- MatMulInteger
- MatMulInteger16
- MatMulIntergerToFloat
- MatMulNBits
- MaxPoolWithMask
- MaxRoiPool
- MaxUnPool
- MelWeightMatrix
- MicrosoftDequantizeLinear
- MicrosoftGatherND
- MicrosoftGridSample
- MicrosoftPad
- MicrosoftQLinearConv
- MicrosoftQuantizeLinear
- MicrosoftRange
- MicrosoftTrilu
- Mod
- MoE
- Mul
- MulInteger
- NegativeLogLikelihoodLoss
- NGramRepeatBlock
- NhwcConv
- NhwcFusedConv
- NonMaxSuppression
- OneHot
- Or
- PackedAttention
- PackedMultiHeadAttention
- Pad
- Pow
- QGemm
- QLinearAdd
- QLinearAveragePool
- QLinearConcat
- QLinearConv
- QLinearGlobalAveragePool
- QLinearLeakyRelu
- QLinearMatMul
- QLinearMul
- QLinearReduceMean
- QLinearSigmoid
- QLinearSoftmax
- QLinearWhere
- QMoE
- QOrderedAttention
- QOrderedGelu
- QOrderedLayerNormalization
- QOrderedLongformerAttention
- QOrderedMatMul
- QuantizeLinear
- QuantizeWithOrder
- Range
- ReduceL1
- ReduceL2
- ReduceLogSum
- ReduceLogSumExp
- ReduceMax
- ReduceMean
- ReduceMin
- ReduceProd
- ReduceSum
- ReduceSumSquare
- RelativePositionBias
- Reshape
- Resize
- RestorePadding
- ReverseSequence
- RoiAlign
- RotaryEmbedding
- ScatterElements
- ScatterND
- SequenceAt
- SequenceErase
- SequenceInsert
- Sinh
- Slice
- SparseToDenseMatMul
- SplitToSequence
- Squeeze
- STFT
- StringConcat
- Sub
- Tile
- TorchEmbedding
- TransposeMatMul
- Trilu
- Unsqueeze
- Where
- WordConvEmbedding
- Xor
- Show All Articles (134) Collapse Articles
-
- Attention
- AttnLSTM
- BatchNormalization
- BiasDropout
- BifurcationDetector
- BitmaskBiasDropout
- BitmaskDropout
- DecoderAttention
- DecoderMaskedMultiHeadAttention
- DecoderMaskedSelfAttention
- Dropout
- DynamicQuantizeLinear
- DynamicQuantizeLSTM
- EmbedLayerNormalization
- GemmaRotaryEmbedding
- GroupQueryAttention
- GRU
- LayerNormalization
- LSTM
- MicrosoftMultiHeadAttention
- QAttention
- RemovePadding
- RNN
- Sampling
- SkipGroupNorm
- SkipLayerNormalization
- SkipSimplifiedLayerNormalization
- SoftmaxCrossEntropyLoss
- SparseAttention
- TopK
- WhisperBeamSearch
- Show All Articles (15) Collapse Articles
-
-
-
-
-
-
-
-
-
-
- AdditiveAttention
- Attention
- BatchNormalization
- Bidirectional
- Conv1D
- Conv2D
- Conv1DTranspose
- Conv2DTranspose
- Conv3DTranspose
- Conv3D
- ConvLSTM1D
- ConvLSTM2D
- ConvLSTM3D
- Dense
- DepthwiseConv2D
- Embedding
- LayerNormalization
- GRU
- LSTM
- PReLU 2D
- PReLU 3D
- PReLU 4D
- PReLU 5D
- MutiHeadAttention
- SeparableConv1D
- SeparableConv2D
- MultiHeadAttention
- RNN (GRU)
- RNN (LSTM)
- RNN (SimpleRNN)
- SimpleRNN
- 1D
- 2D
- 3D
- 4D
- 5D
- 6D
- Scalar
- Show All Articles (22) Collapse Articles
-
- AdditiveAttention
- Attention
- BatchNormalization
- Conv1D
- Conv2D
- Conv1DTranspose
- Conv2DTranspose
- Bidirectional
- Conv3D
- ConvLSTM1D
- ConvLSTM2D
- ConvLSTM3D
- Conv3DTranspose
- DepthwiseConv2D
- Dense
- Embedding
- LayerNormalization
- GRU
- PReLU 2D
- PReLU 3D
- PReLU 4D
- MultiHeadAttention
- LSTM
- PReLU 5D
- SeparableConv1D
- SeparableConv2D
- SimpleRNN
- RNN (GRU)
- RNN (LSTM)
- RNN (SimpleRNN)
- 1D
- 2D
- 3D
- 4D
- 5D
- 6D
- Scalar
- Show All Articles (21) Collapse Articles
-
-
- AdditiveAttention
- Attention
- BatchNormalization
- Bidirectional
- Conv1D
- Conv2D
- Conv3D
- Conv1DTranspose
- Conv2DTranspose
- Conv3DTranspose
- ConvLSTM1D
- ConvLSTM2D
- ConvLSTM3D
- Dense
- DepthwiseConv2D
- Embedding
- GRU
- LayerNormalization
- LSTM
- MultiHeadAttention
- PReLU 2D
- PReLU 3D
- PReLU 4D
- PReLU 5D
- Resume
- SeparableConv1D
- SeparableConv2D
- SimpleRNN
- Show All Articles (12) Collapse Articles
-
-
- Dense
- Embedding
- AdditiveAttention
- Attention
- MultiHeadAttention
- Conv1D
- Conv2D
- Conv3D
- ConvLSTM1D
- ConvLSTM2D
- ConvLSTM3D
- Conv1DTranspose
- Conv2DTranspose
- Conv3DTranspose
- DepthwiseConv2D
- SeparableConv1D
- SeparableConv2D
- BatchNormalization
- LayerNormalization
- PReLU 2D
- PReLU 3D
- PReLU 4D
- PReLU 5D
- Bidirectional
- GRU
- LSTM
- RNN (GRU)
- RNN (LSTM)
- RNN (SimpleRNN)
- SimpleRNN
- PReLU 4D
- Show All Articles (15) Collapse Articles
-
- Dense
- Embedding
- AdditiveAttention
- Attention
- MultiHeadAttention
- Conv1D
- Conv2D
- Conv3D
- ConvLSTM1D
- ConvLSTM2D
- ConvLSTM3D
- Conv1DTranspose
- Conv2DTranspose
- Conv3DTranspose
- DepthwiseConv2D
- SeparableConv1D
- SeparableConv2D
- BatchNormalization
- LayerNormalization
- PReLU 2D
- PReLU 3D
- PReLU 4D
- PReLU 5D
- Bidirectional
- GRU
- LSTM
- RNN (GRU)
- RNN (LSTM)
- RNN (SimpleRNN)
- SimpleRNN
- Show All Articles (14) Collapse Articles
-
-
- Accuracy
- BinaryAccuracy
- BinaryCrossentropy
- BinaryIoU
- CategoricalAccuracy
- CategoricalCrossentropy
- CategoricalHinge
- CosineSimilarity
- FalseNegatives
- FalsePositives
- Hinge
- Huber
- IoU
- KLDivergence
- LogCoshError
- Mean
- MeanAbsoluteError
- MeanAbsolutePercentageError
- MeanIoU
- MeanRelativeError
- MeanSquaredError
- MeanSquaredLogarithmicError
- MeanTensor
- OneHotIoU
- OneHotMeanIoU
- Poisson
- Precision
- PrecisionAtRecall
- Recall
- RecallAtPrecision
- RootMeanSquaredError
- SensitivityAtSpecificity
- SparseCategoricalAccuracy
- SparseCategoricalCrossentropy
- SparseTopKCategoricalAccuracy
- Specificity
- SpecificityAtSensitivity
- SquaredHinge
- Sum
- TopKCategoricalAccuracy
- TrueNegatives
- TruePositives
- Resume
- Show All Articles (27) Collapse Articles
-
-
- Dense
- Embedding
- AdditiveAttention
- Attention
- MultiHeadAttention
- Conv1D
- Conv2D
- Conv3D
- ConvLSTM1D
- ConvLSTM2D
- ConvLSTM3D
- Conv1DTranspose
- Conv2DTranspose
- Conv3DTranspose
- DepthwiseConv2D
- SeparableConv1D
- SeparableConv2D
- BatchNormalization
- LayerNormalization
- PReLU 2D
- PReLU 3D
- PReLU 4D
- PReLU 5D
- Bidirectional
- GRU
- LSTM
- RNN (GRU)
- RNN (LSTM)
- RNN (SimpleRNN)
- SimpleRNN
- Show All Articles (14) Collapse Articles
-
- Dense
- Embedding
- AdditiveAttention
- Attention
- MultiHeadAttention
- Conv1D
- Conv2D
- Conv3D
- ConvLSTM1D
- ConvLSTM2D
- ConvLSTM3D
- Conv1DTranspose
- Conv2DTranspose
- Conv3DTranspose
- DepthwiseConv2D
- SeparableConv1D
- SeparableConv2D
- LayerNormalization
- PReLU 2D
- PReLU 3D
- PReLU 4D
- PReLU 5D
- Bidirectional
- GRU
- LSTM
- RNN (GRU)
- RNN (LSTM)
- RNN (SimpleRNN)
- SimpleRNN
- BatchNormalization
- Show All Articles (14) Collapse Articles
-
-
-
Computer Vision Toolkit
-
CUDA Toolkit
-
- Resume
- Array size
- Index Array
- Replace Subset
- Insert Into Array
- Delete From Array
- Initialize Array
- Build Array
- Concatenate Array
- Array Subset
- Min & Max
- Reshape Array
- Short Array
- Reverse 1D array
- Shuffle array
- Search In Array
- Split 1D Array
- Split 2D Array
- Rotate 1D Array
- Increment Array Element
- Decrement Array Element
- Interpolate 1D Array
- Threshold 1D Array
- Interleave 1D Array
- Decimate 1D Array
- Transpose Array
- Remove Duplicate From 1D Array
- Show All Articles (11) Collapse Articles
-
-
- Resume
- Add
- Substract
- Multiply
- Divide
- Quotient & Remainder
- Increment
- Decrement
- Add Array Element
- Multiply Array Element
- Absolute
- Round To Nearest
- Round Toward -Infinity
- Round Toward +Infinity
- Scale By Power Of Two
- Square Root
- Square
- Negate
- Reciprocal
- Sign
- Show All Articles (4) Collapse Articles
TensorRT
Description
Create Cuda Session with its Session Options on the stored local Env. Type : polymorphic.
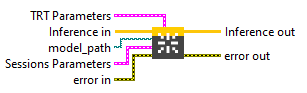
Input parameters
![]() Inference in : object, inference session.
Inference in : object, inference session.![]() model_path : path, is the path to the model file.
model_path : path, is the path to the model file.
![]() Sessions Parameters : cluster
Sessions Parameters : cluster
![]() intra_op_num_threads : integer, number of threads used within each operator to parallelize computations. If the value is 0, ONNX Runtime automatically uses the number of physical CPU cores.
intra_op_num_threads : integer, number of threads used within each operator to parallelize computations. If the value is 0, ONNX Runtime automatically uses the number of physical CPU cores.![]() inter_op_num_threads : integer, number of threads used between operators, to execute multiple graph nodes in parallel. If set to 0, this parameter is ignored when
inter_op_num_threads : integer, number of threads used between operators, to execute multiple graph nodes in parallel. If set to 0, this parameter is ignored when execution_mode is ORT_SEQUENTIAL. In ORT_PARALLEL mode, 0 means ORT automatically selects a suitable number of threads (usually equal to the number of cores).![]() execution_mode : enum, controls whether the graph executes nodes one after another or allows parallel execution when possible.
execution_mode : enum, controls whether the graph executes nodes one after another or allows parallel execution when possible.ORT_SEQUENTIAL runs nodes in order, ORT_PARALLEL runs them concurrently.![]() deterministic_compute : boolean, forces deterministic execution, meaning results will always be identical for the same inputs.
deterministic_compute : boolean, forces deterministic execution, meaning results will always be identical for the same inputs.![]() graph_optimization_level : enum, defines how much ONNX Runtime optimizes the computation graph before running the model.
graph_optimization_level : enum, defines how much ONNX Runtime optimizes the computation graph before running the model.![]() optimized_model_file_path : path, file path to save the optimized model after graph analysis.
optimized_model_file_path : path, file path to save the optimized model after graph analysis.![]() profiling output dir : path, specifies the directory where ONNX Runtime will save profiling output files. If you set this parameter to a valid (non-empty) path, profiling is automatically enabled. However, if the path is empty, profiling will not be activated.
profiling output dir : path, specifies the directory where ONNX Runtime will save profiling output files. If you set this parameter to a valid (non-empty) path, profiling is automatically enabled. However, if the path is empty, profiling will not be activated.

![]() TRT Parameters : cluster
TRT Parameters : cluster
![]() Device And Stream : cluster,
Device And Stream : cluster,
![]() Device Index : integer, ID of the GPU used for inference (default = 0).
Device Index : integer, ID of the GPU used for inference (default = 0).![]() Use Custom Compute Stream? : boolean, if true, uses a user-defined CUDA compute stream instead of the default stream.
Use Custom Compute Stream? : boolean, if true, uses a user-defined CUDA compute stream instead of the default stream.![]() Custom Compute Stream (Pointer) : integer, pointer or reference to the user’s CUDA stream to be used during inference.
Custom Compute Stream (Pointer) : integer, pointer or reference to the user’s CUDA stream to be used during inference.
![]() Parser & Subgraph Options : cluster,
Parser & Subgraph Options : cluster,
![]() Max Partition Attemps : integer, maximum number of attempts for TensorRT to partition and identify compatible subgraphs within the ONNX model.
Max Partition Attemps : integer, maximum number of attempts for TensorRT to partition and identify compatible subgraphs within the ONNX model.![]() Minimum Subgraph Size : integer, minimum number of nodes required in a subgraph before TensorRT can take ownership of it.
Minimum Subgraph Size : integer, minimum number of nodes required in a subgraph before TensorRT can take ownership of it.
![]() Memory & Workspace Management : cluster,
Memory & Workspace Management : cluster,
![]() Max Workspace Memory (Bytes) : integer, maximum workspace memory allocated for TensorRT (0 = use maximum available GPU memory).
Max Workspace Memory (Bytes) : integer, maximum workspace memory allocated for TensorRT (0 = use maximum available GPU memory).![]() Share Memory Between Subgraphs : boolean, if true, allows multiple TensorRT subgraphs to reuse the same execution context and memory buffers.
Share Memory Between Subgraphs : boolean, if true, allows multiple TensorRT subgraphs to reuse the same execution context and memory buffers.![]() Auxiliary Stream Count : integer, defines how many auxiliary CUDA streams are created per main inference stream.
Auxiliary Stream Count : integer, defines how many auxiliary CUDA streams are created per main inference stream.
-
-
-
- -1 = automatic heuristic mode
- 0 = minimize memory usage
- >0 = allow multiple auxiliary streams for parallel execution
-
-
![]() Precision & Numeric Modes : cluster,
Precision & Numeric Modes : cluster,
![]() Enable FP16 : boolean, enables half-precision (float16) computation for faster performance on supported GPUs.
Enable FP16 : boolean, enables half-precision (float16) computation for faster performance on supported GPUs.![]() Enable BF16 : boolean, enables bfloat16 precision for models trained in BF16 format.
Enable BF16 : boolean, enables bfloat16 precision for models trained in BF16 format.![]() Enable INT8 : boolean, enables INT8 quantization for maximum inference speed.
Enable INT8 : boolean, enables INT8 quantization for maximum inference speed.![]() INT8 Calibration Table Name : path, specifies the name or path of the calibration table used for INT8 mode.
INT8 Calibration Table Name : path, specifies the name or path of the calibration table used for INT8 mode.![]() Use Native INT8 Calibration? : boolean, if true, uses the calibration table generated directly by TensorRT.
Use Native INT8 Calibration? : boolean, if true, uses the calibration table generated directly by TensorRT.
![]() Engine Build, Cache & Paths : cluster,
Engine Build, Cache & Paths : cluster,
![]() Enable Engine Caching? : boolean, saves compiled TensorRT engines to disk to avoid rebuilding on future runs.
Enable Engine Caching? : boolean, saves compiled TensorRT engines to disk to avoid rebuilding on future runs.![]() Engine Cache Directory : path, path where the TensorRT engine cache will be stored.
Engine Cache Directory : path, path where the TensorRT engine cache will be stored.![]() Enable Engine Decryption? : boolean, enables support for encrypted engine files.
Enable Engine Decryption? : boolean, enables support for encrypted engine files.![]() Decryption Library Path : path, path to the library used to decrypt TensorRT engine files.
Decryption Library Path : path, path to the library used to decrypt TensorRT engine files.![]() Build Engines Sequentially? : boolean, forces TensorRT to build engines one at a time instead of in parallel.
Build Engines Sequentially? : boolean, forces TensorRT to build engines one at a time instead of in parallel.![]() Enable Timing Cache? : boolean, enables TensorRT’s timing cache to accelerate repeated builds.
Enable Timing Cache? : boolean, enables TensorRT’s timing cache to accelerate repeated builds.![]() Timing Cache Directory : path, path where timing cache data will be stored.
Timing Cache Directory : path, path where timing cache data will be stored.![]() Force Timing Cache Use? : boolean, forces the reuse of the timing cache even if the device profile has changed.
Force Timing Cache Use? : boolean, forces the reuse of the timing cache even if the device profile has changed.![]() Enable Detailed Logs? : boolean, enables detailed logging for each build step and timing stage.
Enable Detailed Logs? : boolean, enables detailed logging for each build step and timing stage.![]() Use Build Heuristics? : boolean, uses heuristic algorithms to reduce engine build time (may affect optimal performance).
Use Build Heuristics? : boolean, uses heuristic algorithms to reduce engine build time (may affect optimal performance).![]() Enable Weight Sparsity? : boolean, allows TensorRT to exploit sparsity in model weights for better performance.
Enable Weight Sparsity? : boolean, allows TensorRT to exploit sparsity in model weights for better performance.![]() Engine Optimization Level (0–5)) : integer, controls the engine builder optimization level.
Engine Optimization Level (0–5)) : integer, controls the engine builder optimization level.
-
-
-
- 0–2 = fast build, reduced performance
- 3 = default balance between speed and quality
- 4–5 = best performance, longer build time
-
-
![]() Paths & Plugins : cluster,
Paths & Plugins : cluster,
![]() Extra Plugin Libraries : array, list (semicolon-separated) of additional plugin library paths to load.
Extra Plugin Libraries : array, list (semicolon-separated) of additional plugin library paths to load.![]() Tactic Source Rules : string, defines which tactic sources TensorRT should include or exclude (e.g. “-CUDNN,+CUBLAS”).
Tactic Source Rules : string, defines which tactic sources TensorRT should include or exclude (e.g. “-CUDNN,+CUBLAS”).![]() Enabled Preview Features : enum, comma-separated list of experimental TensorRT features to enable (e.g. “ALIASED_PLUGIN_IO_10_03”).
Enabled Preview Features : enum, comma-separated list of experimental TensorRT features to enable (e.g. “ALIASED_PLUGIN_IO_10_03”).
![]() Profile Shapes : cluster,
Profile Shapes : cluster,
![]() Minimum Input Shapes : string, specifies the smallest input dimensions used to build the TensorRT engine.
Minimum Input Shapes : string, specifies the smallest input dimensions used to build the TensorRT engine.![]() Maximum Input Shapes : string, specifies the “typical” input size that TensorRT will optimize for.
Maximum Input Shapes : string, specifies the “typical” input size that TensorRT will optimize for.![]() Optimal Input Shapes : string, defines the upper bound for dynamic input dimensions accepted by the engine.
Optimal Input Shapes : string, defines the upper bound for dynamic input dimensions accepted by the engine.
![]() Advanced & DLA / CUDA Graph : cluster,
Advanced & DLA / CUDA Graph : cluster,
![]() Enable DLA Acceleration? : boolean, enables inference execution on NVIDIA’s Deep Learning Accelerator (if supported).
Enable DLA Acceleration? : boolean, enables inference execution on NVIDIA’s Deep Learning Accelerator (if supported).![]() DLA Core Index : integer, selects which DLA core to use (0 = default).
DLA Core Index : integer, selects which DLA core to use (0 = default).![]() Dump TensorRT Subgraphs? : boolean, dumps all TensorRT-compiled subgraphs to disk for debugging.
Dump TensorRT Subgraphs? : boolean, dumps all TensorRT-compiled subgraphs to disk for debugging.![]() Force LayerNorm in FP32? : boolean, forces LayerNorm operations to run in full precision (FP32) for numerical stability.
Force LayerNorm in FP32? : boolean, forces LayerNorm operations to run in full precision (FP32) for numerical stability.![]() Enable CUDA Graph Execution? : boolean, executes the TensorRT engine using CUDA Graph for improved launch efficiency.
Enable CUDA Graph Execution? : boolean, executes the TensorRT engine using CUDA Graph for improved launch efficiency.

Output parameters
![]() Inference out : object, inference session.
Inference out : object, inference session.
Example
All these exemples are snippets PNG, you can drop these Snippet onto the block diagram and get the depicted code added to your VI (Do not forget to install Accelerator library to run it).