
-
SOTA
-
Accelerator Toolkit
-
Deep Learning Toolkit
-
-
- Resume
- Add
- AlphaDropout
- AdditiveAttention
- Attention
- Average
- AvgPool1D
- AvgPool2D
- AvgPool3D
- BatchNormalization
- Bidirectional
- Concatenate
- Conv1D
- Conv1DTranspose
- Conv2D
- Conv2DTranspose
- Conv3D
- Conv3DTranspose
- ConvLSTM1D
- ConvLSTM2D
- ConvLSTM3D
- Dense
- Cropping1D
- Cropping2D
- Cropping3D
- DepthwiseConv2D
- Dropout
- Embedding
- Flatten
- ELU
- Exponential
- GaussianDropout
- GaussianNoise
- GlobalAvgPool1D
- GlobalAvgPool2D
- GlobalAvgPool3D
- GlobalMaxPool1D
- GlobalMaxPool2D
- GlobalMaxPool3D
- GRU
- GELU
- Input
- LayerNormalization
- LSTM
- MaxPool1D
- MaxPool2D
- MaxPool3D
- MultiHeadAttention
- HardSigmoid
- LeakyReLU
- Linear
- Multiply
- Permute3D
- Reshape
- RNN
- PReLU
- ReLU
- SELU
- Output Predict
- Output Train
- SeparableConv1D
- SeparableConv2D
- SimpleRNN
- SpatialDropout
- Sigmoid
- SoftMax
- SoftPlus
- SoftSign
- Split
- UpSampling1D
- UpSampling2D
- UpSampling3D
- ZeroPadding1D
- ZeroPadding2D
- ZeroPadding3D
- Swish
- TanH
- ThresholdedReLU
- Substract
- Show All Articles (63) Collapse Articles
-
-
-
-
- Exp
- Identity
- Abs
- Acos
- Acosh
- ArgMax
- ArgMin
- Asin
- Asinh
- Atan
- Atanh
- AveragePool
- Bernouilli
- BitwiseNot
- BlackmanWindow
- Cast
- Ceil
- Celu
- ConcatFromSequence
- Cos
- Cosh
- DepthToSpace
- Det
- DynamicTimeWarping
- Erf
- EyeLike
- Flatten
- Floor
- GlobalAveragePool
- GlobalLpPool
- GlobalMaxPool
- HammingWindow
- HannWindow
- HardSwish
- HardMax
- lrfft
- lsNaN
- Log
- LogSoftmax
- LpNormalization
- LpPool
- LRN
- MeanVarianceNormalization
- MicrosoftGelu
- Mish
- Multinomial
- MurmurHash3
- Neg
- NhwcMaxPool
- NonZero
- Not
- OptionalGetElement
- OptionalHasElement
- QuickGelu
- RandomNormalLike
- RandomUniformLike
- RawConstantOfShape
- Reciprocal
- ReduceSumInteger
- RegexFullMatch
- Rfft
- Round
- SampleOp
- Shape
- SequenceLength
- Shrink
- Sin
- Sign
- Sinh
- Size
- SpaceToDepth
- Sqrt
- StringNormalizer
- Tan
- TfldfVectorizer
- Tokenizer
- Transpose
- UnfoldTensor
- lslnf
- ImageDecoder
- Inverse
- Show All Articles (65) Collapse Articles
-
-
-
- Add
- AffineGrid
- And
- BiasAdd
- BiasGelu
- BiasSoftmax
- BiasSplitGelu
- BitShift
- BitwiseAnd
- BitwiseOr
- BitwiseXor
- CastLike
- CDist
- CenterCropPad
- Clip
- Col2lm
- ComplexMul
- ComplexMulConj
- Compress
- ConvInteger
- Conv
- ConvTranspose
- ConvTransposeWithDynamicPads
- CropAndResize
- CumSum
- DeformConv
- DequantizeBFP
- DequantizeLinear
- DequantizeWithOrder
- DFT
- Div
- DynamicQuantizeMatMul
- Equal
- Expand
- ExpandDims
- FastGelu
- FusedConv
- FusedGemm
- FusedMatMul
- FusedMatMulActivation
- GatedRelativePositionBias
- Gather
- GatherElements
- GatherND
- Gemm
- GemmFastGelu
- GemmFloat8
- Greater
- GreaterOrEqual
- GreedySearch
- GridSample
- GroupNorm
- InstanceNormalization
- Less
- LessOrEqual
- LongformerAttention
- MatMul
- MatMulBnb4
- MatMulFpQ4
- MatMulInteger
- MatMulInteger16
- MatMulIntergerToFloat
- MatMulNBits
- MaxPoolWithMask
- MaxRoiPool
- MaxUnPool
- MelWeightMatrix
- MicrosoftDequantizeLinear
- MicrosoftGatherND
- MicrosoftGridSample
- MicrosoftPad
- MicrosoftQLinearConv
- MicrosoftQuantizeLinear
- MicrosoftRange
- MicrosoftTrilu
- Mod
- MoE
- Mul
- MulInteger
- NegativeLogLikelihoodLoss
- NGramRepeatBlock
- NhwcConv
- NhwcFusedConv
- NonMaxSuppression
- OneHot
- Or
- PackedAttention
- PackedMultiHeadAttention
- Pad
- Pow
- QGemm
- QLinearAdd
- QLinearAveragePool
- QLinearConcat
- QLinearConv
- QLinearGlobalAveragePool
- QLinearLeakyRelu
- QLinearMatMul
- QLinearMul
- QLinearReduceMean
- QLinearSigmoid
- QLinearSoftmax
- QLinearWhere
- QMoE
- QOrderedAttention
- QOrderedGelu
- QOrderedLayerNormalization
- QOrderedLongformerAttention
- QOrderedMatMul
- QuantizeLinear
- QuantizeWithOrder
- Range
- ReduceL1
- ReduceL2
- ReduceLogSum
- ReduceLogSumExp
- ReduceMax
- ReduceMean
- ReduceMin
- ReduceProd
- ReduceSum
- ReduceSumSquare
- RelativePositionBias
- Reshape
- Resize
- RestorePadding
- ReverseSequence
- RoiAlign
- RotaryEmbedding
- ScatterElements
- ScatterND
- SequenceAt
- SequenceErase
- SequenceInsert
- Sinh
- Slice
- SparseToDenseMatMul
- SplitToSequence
- Squeeze
- STFT
- StringConcat
- Sub
- Tile
- TorchEmbedding
- TransposeMatMul
- Trilu
- Unsqueeze
- Where
- WordConvEmbedding
- Xor
- Show All Articles (134) Collapse Articles
-
- Attention
- AttnLSTM
- BatchNormalization
- BiasDropout
- BifurcationDetector
- BitmaskBiasDropout
- BitmaskDropout
- DecoderAttention
- DecoderMaskedMultiHeadAttention
- DecoderMaskedSelfAttention
- Dropout
- DynamicQuantizeLinear
- DynamicQuantizeLSTM
- EmbedLayerNormalization
- GemmaRotaryEmbedding
- GroupQueryAttention
- GRU
- LayerNormalization
- LSTM
- MicrosoftMultiHeadAttention
- QAttention
- RemovePadding
- RNN
- Sampling
- SkipGroupNorm
- SkipLayerNormalization
- SkipSimplifiedLayerNormalization
- SoftmaxCrossEntropyLoss
- SparseAttention
- TopK
- WhisperBeamSearch
- Show All Articles (15) Collapse Articles
-
-
-
-
-
-
-
-
-
-
- AdditiveAttention
- Attention
- BatchNormalization
- Bidirectional
- Conv1D
- Conv2D
- Conv1DTranspose
- Conv2DTranspose
- Conv3DTranspose
- Conv3D
- ConvLSTM1D
- ConvLSTM2D
- ConvLSTM3D
- Dense
- DepthwiseConv2D
- Embedding
- LayerNormalization
- GRU
- LSTM
- PReLU 2D
- PReLU 3D
- PReLU 4D
- PReLU 5D
- MutiHeadAttention
- SeparableConv1D
- SeparableConv2D
- MultiHeadAttention
- RNN (GRU)
- RNN (LSTM)
- RNN (SimpleRNN)
- SimpleRNN
- 1D
- 2D
- 3D
- 4D
- 5D
- 6D
- Scalar
- Show All Articles (22) Collapse Articles
-
- AdditiveAttention
- Attention
- BatchNormalization
- Conv1D
- Conv2D
- Conv1DTranspose
- Conv2DTranspose
- Bidirectional
- Conv3D
- ConvLSTM1D
- ConvLSTM2D
- ConvLSTM3D
- Conv3DTranspose
- DepthwiseConv2D
- Dense
- Embedding
- LayerNormalization
- GRU
- PReLU 2D
- PReLU 3D
- PReLU 4D
- MultiHeadAttention
- LSTM
- PReLU 5D
- SeparableConv1D
- SeparableConv2D
- SimpleRNN
- RNN (GRU)
- RNN (LSTM)
- RNN (SimpleRNN)
- 1D
- 2D
- 3D
- 4D
- 5D
- 6D
- Scalar
- Show All Articles (21) Collapse Articles
-
-
- AdditiveAttention
- Attention
- BatchNormalization
- Bidirectional
- Conv1D
- Conv2D
- Conv3D
- Conv1DTranspose
- Conv2DTranspose
- Conv3DTranspose
- ConvLSTM1D
- ConvLSTM2D
- ConvLSTM3D
- Dense
- DepthwiseConv2D
- Embedding
- GRU
- LayerNormalization
- LSTM
- MultiHeadAttention
- PReLU 2D
- PReLU 3D
- PReLU 4D
- PReLU 5D
- Resume
- SeparableConv1D
- SeparableConv2D
- SimpleRNN
- Show All Articles (12) Collapse Articles
-
-
- Dense
- Embedding
- AdditiveAttention
- Attention
- MultiHeadAttention
- Conv1D
- Conv2D
- Conv3D
- ConvLSTM1D
- ConvLSTM2D
- ConvLSTM3D
- Conv1DTranspose
- Conv2DTranspose
- Conv3DTranspose
- DepthwiseConv2D
- SeparableConv1D
- SeparableConv2D
- BatchNormalization
- LayerNormalization
- PReLU 2D
- PReLU 3D
- PReLU 4D
- PReLU 5D
- Bidirectional
- GRU
- LSTM
- RNN (GRU)
- RNN (LSTM)
- RNN (SimpleRNN)
- SimpleRNN
- PReLU 4D
- Show All Articles (15) Collapse Articles
-
- Dense
- Embedding
- AdditiveAttention
- Attention
- MultiHeadAttention
- Conv1D
- Conv2D
- Conv3D
- ConvLSTM1D
- ConvLSTM2D
- ConvLSTM3D
- Conv1DTranspose
- Conv2DTranspose
- Conv3DTranspose
- DepthwiseConv2D
- SeparableConv1D
- SeparableConv2D
- BatchNormalization
- LayerNormalization
- PReLU 2D
- PReLU 3D
- PReLU 4D
- PReLU 5D
- Bidirectional
- GRU
- LSTM
- RNN (GRU)
- RNN (LSTM)
- RNN (SimpleRNN)
- SimpleRNN
- Show All Articles (14) Collapse Articles
-
-
- Accuracy
- BinaryAccuracy
- BinaryCrossentropy
- BinaryIoU
- CategoricalAccuracy
- CategoricalCrossentropy
- CategoricalHinge
- CosineSimilarity
- FalseNegatives
- FalsePositives
- Hinge
- Huber
- IoU
- KLDivergence
- LogCoshError
- Mean
- MeanAbsoluteError
- MeanAbsolutePercentageError
- MeanIoU
- MeanRelativeError
- MeanSquaredError
- MeanSquaredLogarithmicError
- MeanTensor
- OneHotIoU
- OneHotMeanIoU
- Poisson
- Precision
- PrecisionAtRecall
- Recall
- RecallAtPrecision
- RootMeanSquaredError
- SensitivityAtSpecificity
- SparseCategoricalAccuracy
- SparseCategoricalCrossentropy
- SparseTopKCategoricalAccuracy
- Specificity
- SpecificityAtSensitivity
- SquaredHinge
- Sum
- TopKCategoricalAccuracy
- TrueNegatives
- TruePositives
- Resume
- Show All Articles (27) Collapse Articles
-
-
- Dense
- Embedding
- AdditiveAttention
- Attention
- MultiHeadAttention
- Conv1D
- Conv2D
- Conv3D
- ConvLSTM1D
- ConvLSTM2D
- ConvLSTM3D
- Conv1DTranspose
- Conv2DTranspose
- Conv3DTranspose
- DepthwiseConv2D
- SeparableConv1D
- SeparableConv2D
- BatchNormalization
- LayerNormalization
- PReLU 2D
- PReLU 3D
- PReLU 4D
- PReLU 5D
- Bidirectional
- GRU
- LSTM
- RNN (GRU)
- RNN (LSTM)
- RNN (SimpleRNN)
- SimpleRNN
- Show All Articles (14) Collapse Articles
-
- Dense
- Embedding
- AdditiveAttention
- Attention
- MultiHeadAttention
- Conv1D
- Conv2D
- Conv3D
- ConvLSTM1D
- ConvLSTM2D
- ConvLSTM3D
- Conv1DTranspose
- Conv2DTranspose
- Conv3DTranspose
- DepthwiseConv2D
- SeparableConv1D
- SeparableConv2D
- LayerNormalization
- PReLU 2D
- PReLU 3D
- PReLU 4D
- PReLU 5D
- Bidirectional
- GRU
- LSTM
- RNN (GRU)
- RNN (LSTM)
- RNN (SimpleRNN)
- SimpleRNN
- BatchNormalization
- Show All Articles (14) Collapse Articles
-
-
-
Computer Vision Toolkit
-
CUDA Toolkit
-
- Resume
- Array size
- Index Array
- Replace Subset
- Insert Into Array
- Delete From Array
- Initialize Array
- Build Array
- Concatenate Array
- Array Subset
- Min & Max
- Reshape Array
- Short Array
- Reverse 1D array
- Shuffle array
- Search In Array
- Split 1D Array
- Split 2D Array
- Rotate 1D Array
- Increment Array Element
- Decrement Array Element
- Interpolate 1D Array
- Threshold 1D Array
- Interleave 1D Array
- Decimate 1D Array
- Transpose Array
- Remove Duplicate From 1D Array
- Show All Articles (11) Collapse Articles
-
-
- Resume
- Add
- Substract
- Multiply
- Divide
- Quotient & Remainder
- Increment
- Decrement
- Add Array Element
- Multiply Array Element
- Absolute
- Round To Nearest
- Round Toward -Infinity
- Round Toward +Infinity
- Scale By Power Of Two
- Square Root
- Square
- Negate
- Reciprocal
- Sign
- Show All Articles (4) Collapse Articles
Resize
Description
Resize the input tensor. In general, it calculates every value in the output tensor as a weighted average of neighborhood (a.k.a. sampling locations) in the input tensor. Each dimension value of the output tensor is : output_dimension = floor(input_dimension * (roi_end – roi_start) * scale), if input “sizes” is not specified.
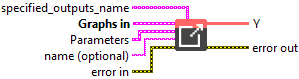
Input parameters
![]() specified_outputs_name : array, this parameter lets you manually assign custom names to the output tensors of a node.
specified_outputs_name : array, this parameter lets you manually assign custom names to the output tensors of a node.
![]() Graphs in : cluster, ONNX model architecture.
Graphs in : cluster, ONNX model architecture.
![]() X (heterogeneous) – T1 : object, N-D tensor.
X (heterogeneous) – T1 : object, N-D tensor.![]() roi (optional, heterogeneous) – T2 : object, 1-D tensor given as [start1, …, startN, end1, …, endN], where N is the rank of X or the length of axes, if provided. The RoIs’ coordinates are normalized in the coordinate system of the input image. It only takes effect when coordinate_transformation_mode is “tf_crop_and_resize”.
roi (optional, heterogeneous) – T2 : object, 1-D tensor given as [start1, …, startN, end1, …, endN], where N is the rank of X or the length of axes, if provided. The RoIs’ coordinates are normalized in the coordinate system of the input image. It only takes effect when coordinate_transformation_mode is “tf_crop_and_resize”.![]() scales (optional, heterogeneous) – tensor(float) : object, the scale array along each dimension. It takes value greater than 0. If it’s less than 1, it’s sampling down, otherwise, it’s upsampling. The number of elements of ‘scales’ should be the same as the rank of input ‘X’ or the length of ‘axes’, if provided. One of ‘scales’ and ‘sizes’ MUST be specified and it is an error if both are specified. If ‘sizes’ is needed, the user can use an empty string as the name of ‘scales’ in this operator’s input list.
scales (optional, heterogeneous) – tensor(float) : object, the scale array along each dimension. It takes value greater than 0. If it’s less than 1, it’s sampling down, otherwise, it’s upsampling. The number of elements of ‘scales’ should be the same as the rank of input ‘X’ or the length of ‘axes’, if provided. One of ‘scales’ and ‘sizes’ MUST be specified and it is an error if both are specified. If ‘sizes’ is needed, the user can use an empty string as the name of ‘scales’ in this operator’s input list.![]() sizes (optional, heterogeneous) – tensor(int64) : object, target size of the output tensor. Its interpretation depends on the ‘keep_aspect_ratio_policy’ value.The number of elements of ‘sizes’ should be the same as the rank of input ‘X’, or the length of ‘axes’, if provided. Only one of ‘scales’ and ‘sizes’ can be specified.
sizes (optional, heterogeneous) – tensor(int64) : object, target size of the output tensor. Its interpretation depends on the ‘keep_aspect_ratio_policy’ value.The number of elements of ‘sizes’ should be the same as the rank of input ‘X’, or the length of ‘axes’, if provided. Only one of ‘scales’ and ‘sizes’ can be specified.

![]() Parameters : cluster,
Parameters : cluster,
![]() antialias : boolean, if set to true, “linear” and “cubic” interpolation modes will use an antialiasing filter when downscaling. Antialiasing is achieved by stretching the resampling filter by a factor max(1, 1 / scale), which means that when downsampling, more input pixels contribute to an output pixel.
antialias : boolean, if set to true, “linear” and “cubic” interpolation modes will use an antialiasing filter when downscaling. Antialiasing is achieved by stretching the resampling filter by a factor max(1, 1 / scale), which means that when downsampling, more input pixels contribute to an output pixel.
Default value “False”.![]() axes : array, if provided, it specifies a subset of axes that ‘roi’, ‘scales’ and ‘sizes’ refer to. If not provided, all axes are assumed [0, 1, …, r-1], where r = rank(data). Non-specified dimensions are interpreted as non-resizable. Negative value means counting dimensions from the back. Accepted range is [-r, r-1], where r = rank(data). Behavior is undefined if an axis is repeated.
axes : array, if provided, it specifies a subset of axes that ‘roi’, ‘scales’ and ‘sizes’ refer to. If not provided, all axes are assumed [0, 1, …, r-1], where r = rank(data). Non-specified dimensions are interpreted as non-resizable. Negative value means counting dimensions from the back. Accepted range is [-r, r-1], where r = rank(data). Behavior is undefined if an axis is repeated.
Default value “empty”.![]() coordinate_transformation_mode : enum, this attribute describes how to transform the coordinate in the resized tensor to the coordinate in the original tensor.
coordinate_transformation_mode : enum, this attribute describes how to transform the coordinate in the resized tensor to the coordinate in the original tensor.
Default value “half_pixel”.![]() cubic_coeff_a : float, the coefficient ‘a’ used in cubic interpolation. Two common choice are -0.5 (in some cases of TensorFlow) and -0.75 (in PyTorch). Check out Equation (4) in https://ieeexplore.ieee.org/document/1163711 for the details. This attribute is valid only if mode is “cubic”.
cubic_coeff_a : float, the coefficient ‘a’ used in cubic interpolation. Two common choice are -0.5 (in some cases of TensorFlow) and -0.75 (in PyTorch). Check out Equation (4) in https://ieeexplore.ieee.org/document/1163711 for the details. This attribute is valid only if mode is “cubic”.
Default value “-0.75”.![]() exclude_outside : boolean, if set to true, the weight of sampling locations outside the tensor will be set to 0 and the weight will be renormalized so that their sum is 1.0.
exclude_outside : boolean, if set to true, the weight of sampling locations outside the tensor will be set to 0 and the weight will be renormalized so that their sum is 1.0.
Default value “False”.![]() extrapolation_value : float, when coordinate_transformation_mode is “tf_crop_and_resize” and x_original is outside the range [0, length_original – 1], this value is used as the corresponding output value.
extrapolation_value : float, when coordinate_transformation_mode is “tf_crop_and_resize” and x_original is outside the range [0, length_original – 1], this value is used as the corresponding output value.
Default value “0”.![]() keep_aspect_ratio_policy : enum, this attribute describes how to interpret the
keep_aspect_ratio_policy : enum, this attribute describes how to interpret the sizes input with regard to keeping the original aspect ratio of the input, and it is not applicable when the scales input is used.
Default value “stretch”.![]() mode : enum, three interpolation modes: “nearest” (default), “linear” and “cubic”. The “linear” mode includes linear interpolation for 1D tensor and N-linear interpolation for N-D tensor (for example, bilinear interpolation for 2D tensor). The “cubic” mode includes cubic interpolation for 1D tensor and N-cubic interpolation for N-D tensor (for example, bicubic interpolation for 2D tensor).
mode : enum, three interpolation modes: “nearest” (default), “linear” and “cubic”. The “linear” mode includes linear interpolation for 1D tensor and N-linear interpolation for N-D tensor (for example, bilinear interpolation for 2D tensor). The “cubic” mode includes cubic interpolation for 1D tensor and N-cubic interpolation for N-D tensor (for example, bicubic interpolation for 2D tensor).
Default value “nearest”.![]() nearest_mode : enum, four modes: “round_prefer_floor” (default, as known as round half down), “round_prefer_ceil” (as known as round half up), “floor”, “ceil”. Only used by nearest interpolation. It indicates how to get “nearest” pixel in input tensor from x_original, so this attribute is valid only if “mode” is “nearest”.
nearest_mode : enum, four modes: “round_prefer_floor” (default, as known as round half down), “round_prefer_ceil” (as known as round half up), “floor”, “ceil”. Only used by nearest interpolation. It indicates how to get “nearest” pixel in input tensor from x_original, so this attribute is valid only if “mode” is “nearest”.
Default value “round_prefer_floor”.![]() training? : boolean, whether the layer is in training mode (can store data for backward).
training? : boolean, whether the layer is in training mode (can store data for backward).
Default value “True”.![]() lda coeff : float, defines the coefficient by which the loss derivative will be multiplied before being sent to the previous layer (since during the backward run we go backwards).
lda coeff : float, defines the coefficient by which the loss derivative will be multiplied before being sent to the previous layer (since during the backward run we go backwards).
Default value “1”.
![]() name (optional) : string, name of the node.
name (optional) : string, name of the node.

Output parameters
![]() Y (heterogeneous) – T1 : object, N-D tensor after resizing.
Y (heterogeneous) – T1 : object, N-D tensor after resizing.
Type Constraints
T1 in (tensor(bfloat16), tensor(bool), tensor(complex128), tensor(complex64), tensor(double), tensor(float), tensor(float16), tensor(int16), tensor(int32), tensor(int64), tensor(int8), tensor(string), tensor(uint16), tensor(uint32), tensor(uint64), tensor(uint8)) : Constrain input ‘X’ and output ‘Y’ to all tensor types.
T2 in (tensor(double), tensor(float), tensor(float16)) : Constrain roi type to float or double.