We are excited to announce the integration of Florence-2, Microsoft’s revolutionary vision-language model, into our LabVIEW Deep Learning suite. Leveraging the major advantage of LabVIEW over traditional syntactic languages, namely the rapid implementation of agents through an efficient and adapted software architecture, we have decided to develop a new generation of modules and tools for LabVIEW focused on robotics, AI, and automation.
Introduction to Florence-2
Unveiled by Microsoft in June 2024, Florence-2 is a unified vision-language model capable of executing a variety of computer vision and vision-language tasks using a prompt-based representation architecture. This model is designed to handle simple textual instructions and produce desired outcomes in text form, covering tasks such as image captioning, object detection, segmentation, and optical character recognition (OCR) (Hugging Face) (MicroCloud).
Capabilities and Performance
Florence-2 is available in two sizes: Florence-2-base with 0.23 billion parameters and Florence-2-large with 0.77 billion parameters. Despite its compact size, it outperforms much larger models like Kosmos-2 in zero-shot and fine-tuning performance (Roboflow Blog) (WinBuzzer). Florence-2 was trained on a vast dataset named FLD-5B, containing 126 million images and over 5 billion annotations, enabling it to excel in various vision tasks without requiring specific models for each task (EZML).
Model Architecture
Florence-2 is a multimodal vision-language model, meaning it can handle both visual and textual inputs. Its architecture is designed to facilitate automatic image understanding and annotation. Here is an overview of its architecture:

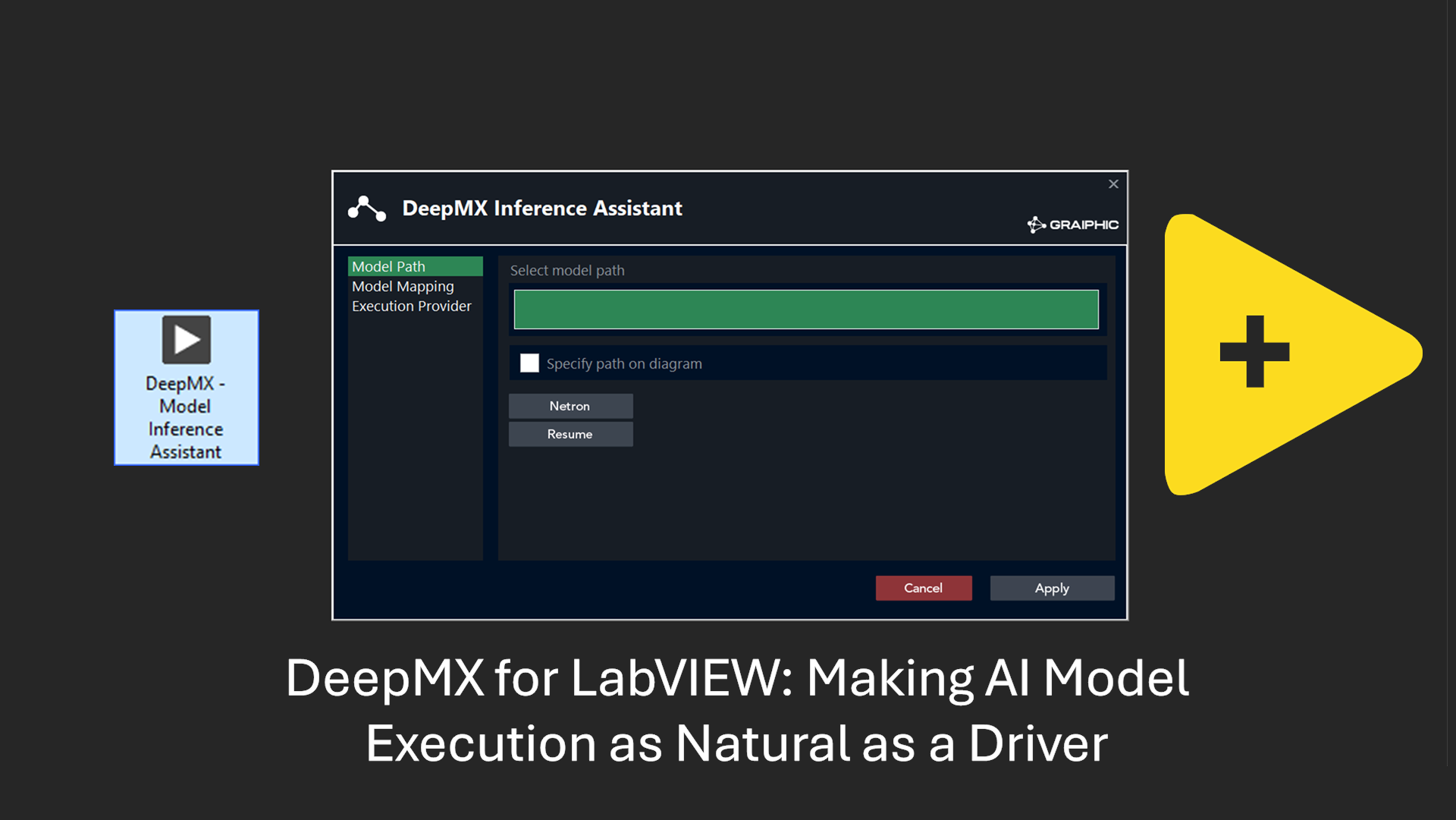
To integrate Florence-2 with LabVIEW, we had to work extensively to reproduce its operational architecture from the available ONNX files: decoder_model.onnx, decoder_model_merged.onnx, decoder_model_merged_plus_scores.onnx, decoder_model_plus_scores.onnx, embed_tokens.onnx, encoder_model.onnx, logits_scores.onnx, topk_node.onnx, vision_encoder.onnx. We performed reverse engineering using the Hugging Face Transformer library due to the lack of documentation, which was a highly interesting exercise. We now have four models available: base, base ft (fine-tuned), large, and large ft.
Integration into LabVIEW
With the LabVIEW deep learning module, LabVIEW users will soon be able to benefit from advanced features to run models like Florence-2. This module will enable these models to operate on LabVIEW, providing top-tier performance for complex computer vision tasks. Key features offered by this toolkit include:
- Full compatibility with existing frameworks: Keras, TensorFlow, PyTorch, ONNX.
- Impressive performance: The new LabVIEW deep learning tools will allow executions 50 times faster than the previous generation and 20% faster than PyTorch.
- Extended hardware support: CUDA, TensorRT for NVIDIA, Rocm for AMD, OneAPI for Intel.
- Maximum modularity: Define your own layers and loss functions.
- Graph neural networks: Complete and advanced integration.
- Annotation tools: An annotator as efficient as Roboflow, integrated into our software suite.
- Model visualization: Utilizing Netron for graphical model summaries.
- Generative AI: Complete library for execution, fine-tuning, and RAG setup for Llama 3 and Phi 3 models.
Example Video
In this video, we demonstrate the Florence-2 model operating as an agent within a state machine architecture. This setup allows users to easily load images and select model prompts. The example will be downloadable with the release of the toolkit in October. We utilized the LabVIEW deep learning module and the computer vision module for display, both included in the “SOTA” suite releasing in October.
Conclusion
With the upcoming LabVIEW Deep Learning module, Florence-2 will be available as an example, providing a foundation for users to easily fine-tune it for specific applications in the future. This development marks a new era in automation and robotics, where computer vision tasks become more accessible and efficient. Prepare to explore these new features in October, and stay tuned for more updates and demonstrations.