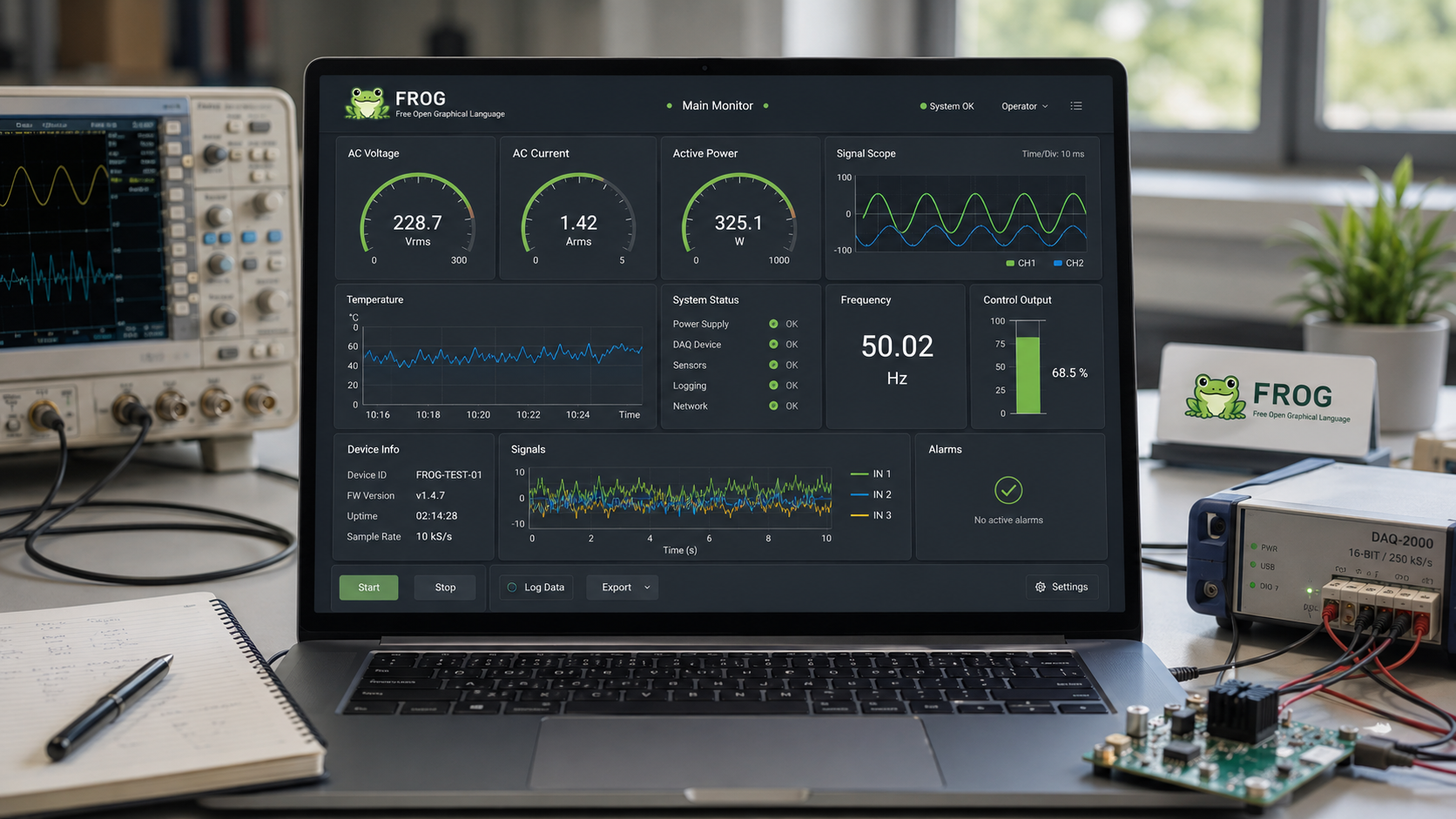
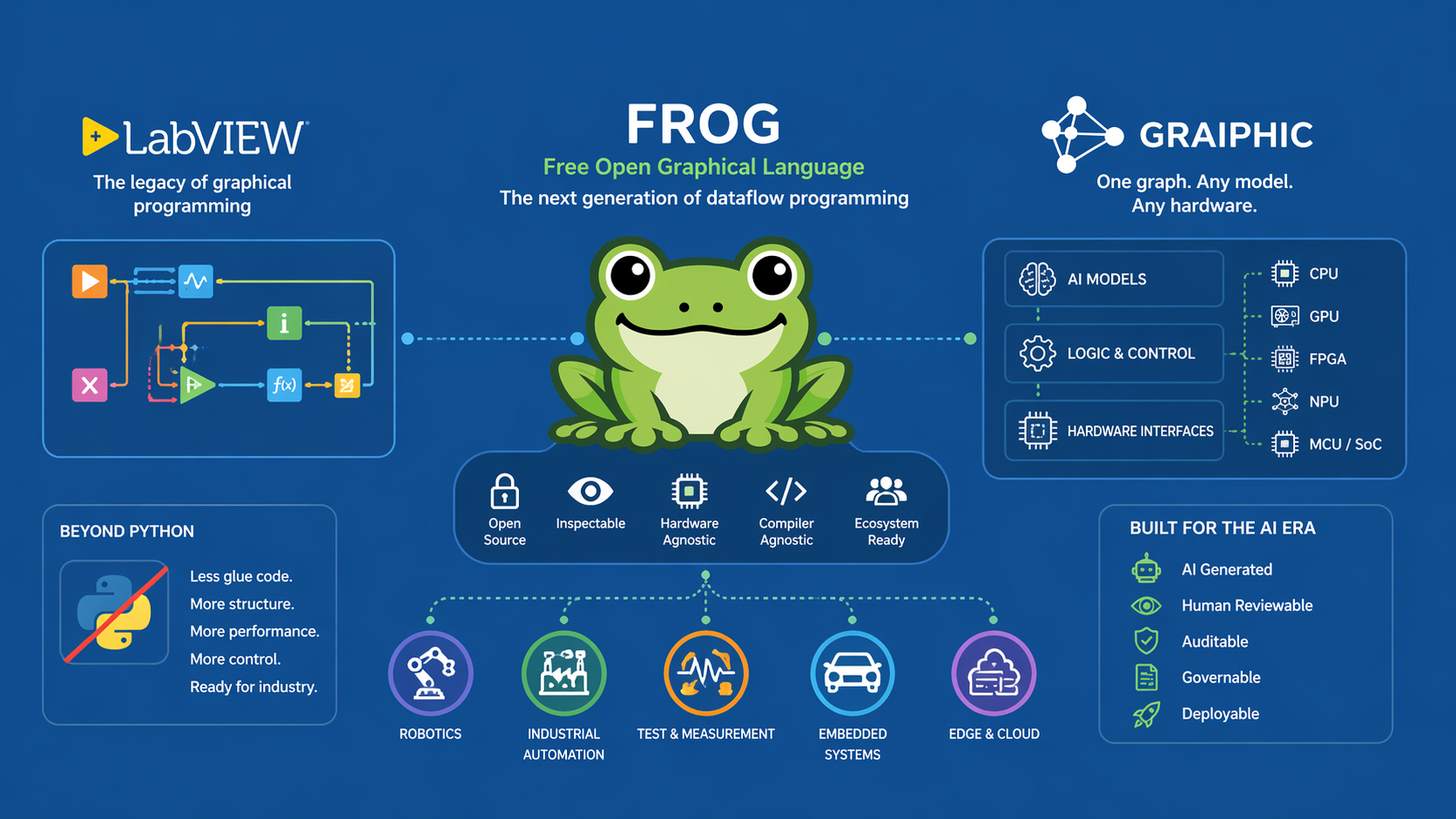
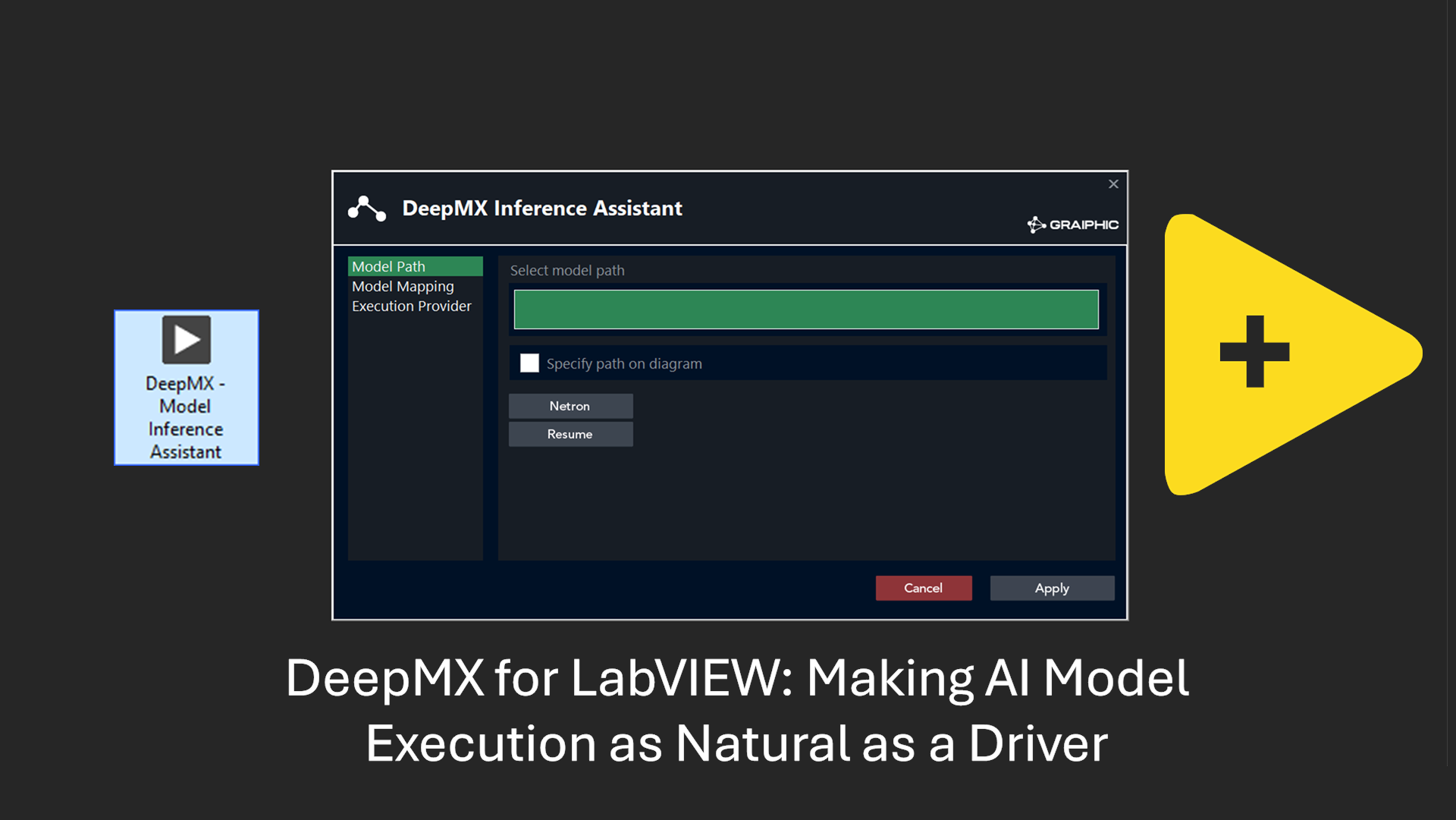
Introducing the vit-face-expression Model
Among our latest innovations is the vit-face-expression model, a Vision Transformer fine-tuned for the specialized task of facial emotion recognition. This model represents a fine-tuned version of the google/vit-base-patch16-224-in21k and has been meticulously trained on the FER2013, MMI Facial Expression Database, and AffectNet datasets. These datasets include a vast array of facial images, each categorized into one of seven distinct emotions: Angry, Disgust, Fear, Happy, Sad, Surprise, and Neutral.
Performance and Evaluation
The vit-face-expression model has undergone rigorous testing and evaluation, achieving impressive results on the evaluation set:
- Loss: 0.4503
- Accuracy: 0.8434
Model Description
The vit-face-expression model is a Vision Transformer (ViT) that has been fine-tuned specifically for facial emotion recognition tasks. By leveraging the rich and diverse data from FER2013, MMI Facial Expression, and AffectNet datasets, the model is capable of accurately identifying and categorizing emotions from facial images. This makes it a powerful tool for applications that require a nuanced understanding of human emotions, such as human-computer interaction, mental health assessments, and more.
Applications and Future Developments
With the continuous advancements in AI and machine learning, the integration of sophisticated models like vit-face-expression into LabVIEW opens up numerous possibilities. We are committed to further expanding our suite of tools and modules to support a wide range of applications in robotics, AI, and automation, ensuring that our solutions remain at the forefront of innovation.
In this video, we demonstrate the VIT face expression model operating as an agent within a state machine architecture. This setup enables users to easily load images and select model prompts. The example will be available for download with the release of the toolkit in October. We utilized the LabVIEW Deep Learning module for inference and the Computer Vision module for display, both included in the “SOTA” suite, also set to release in October.
Stay tuned and follow us on LinkedIn for the latest updates and news! Follow us on LinkedIn https://www.linkedin.com/company/graiphic
🤗 huggingface 👉 https://huggingface.co/trpakov/vit-face-expression
Paper 👉 https://arxiv.org/pdf/2103.16854