- This topic has 23 replies, 2 voices, and was last updated March 12 by
 Youssef MENJOUR.
Youssef MENJOUR.
-
CreatorTopic
-
February 23, 2023 at 11:20 am #57837
Dear Youssef,
1.)
I wanted to reprogram the medical UNet to work with parallel loops (like your Mnist example). Then I got a memory error.
In order to go troubleshooting, I then assumed your Med Unet VI, which works without any problems.
I copied your VI, exchanged the pictue displays for NI Vision and tried to train with the same dataset that I sent you.
Unfortunately, the memory error message keeps coming back. (see picture). Can I send you the VI?
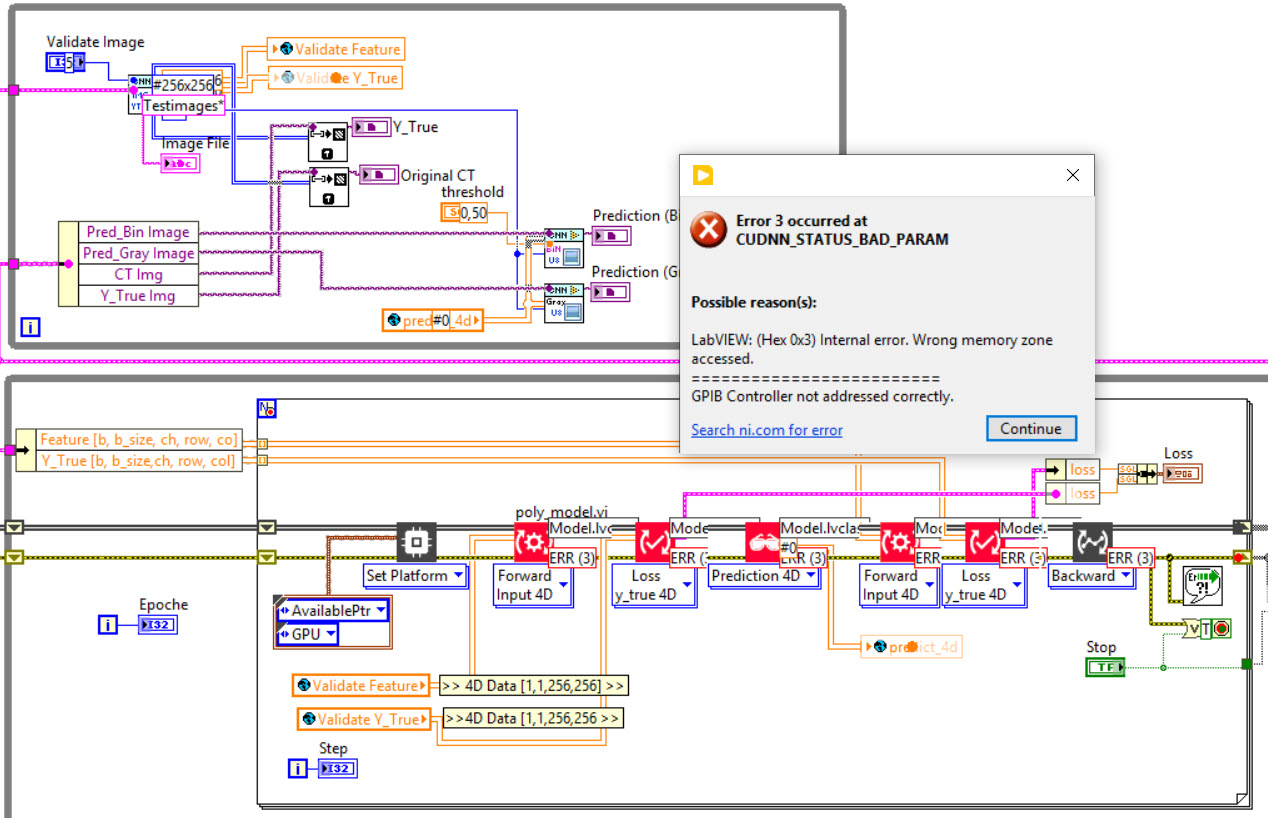
I do not know how to continue.Error Message: Error 3 occured at CUDNN_STATUS_BAD_PARAM. Internal Error. Wrong memory zone accessed.
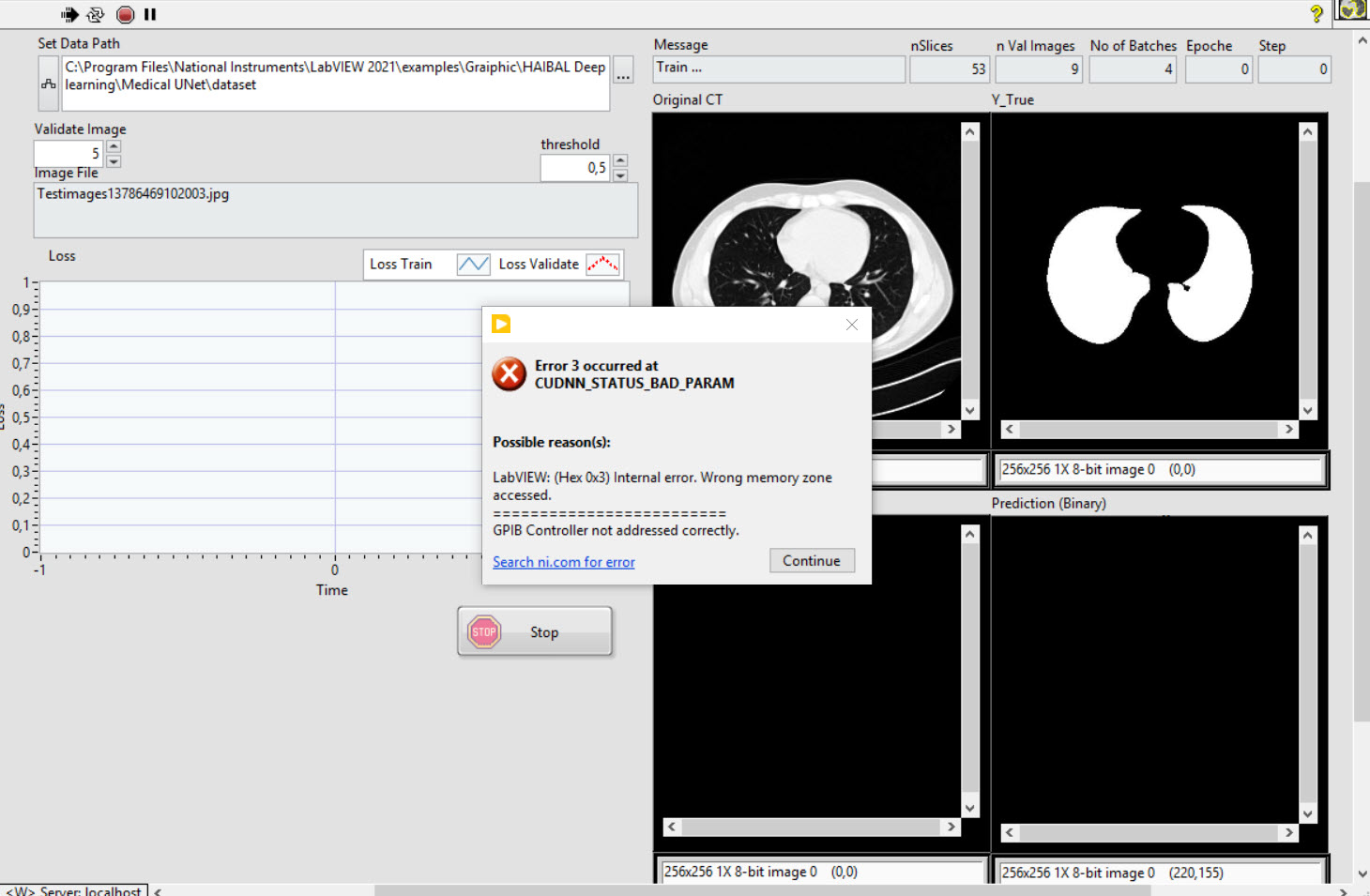
2.) I would then like to determine the accuracy of the prediction for the ground truth image. This is usually done with Intersection-over-Union (=Jacaard Index), or the DICE coefficient. Does the HAIBAL library have such a metric?
Thank you for your help
Peter -
CreatorTopic
-
AuthorReplies
-
February 23, 2023 at 11:31 am #57838
Hi Peter,
Could you please screenshot your diagram.
We know this error since 2 weeks and the next release fix this cuda memory management bug.It’s because you currently doing parrallele achitecture. If you keep in sequential you’ll no more have this problem otherwise we are preparing an update for end of the week giving you the capability to architecture as you like.
February 23, 2023 at 1:51 pm #57839Hi peter,
Sorry i didn’t saw your second question.
We actually working on metrics and we’ll add in future release a complete library.We can integrate this such of metric. Could you tell me more (examples, web reference …). We will do necessary for you. 🙂
For your information, actually metrics are CPU but in the future if you want to GPU also metrics, we will do it.
-
This reply was modified 3 years ago by Youssef MENJOUR.
February 23, 2023 at 2:01 pm #57841Hi Youssef,
Is the same architecture as you use, so with global variables, only with NI Vision. But I get the CUDA error message. Your Unet Example runs without errors.
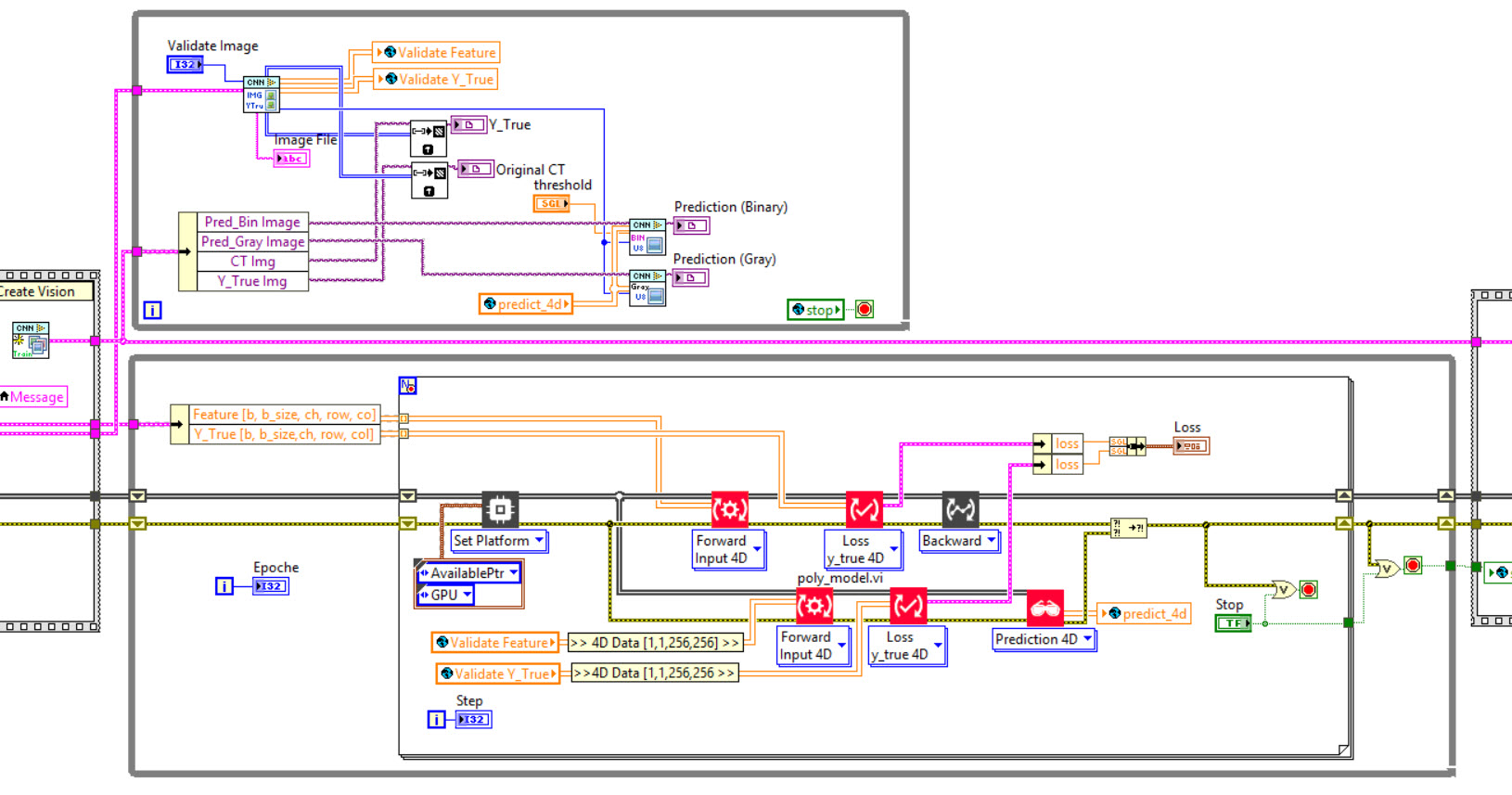 February 23, 2023 at 2:24 pm #57842
February 23, 2023 at 2:24 pm #57842Hi Youssef,
The IOU and DICE calculations and a few links
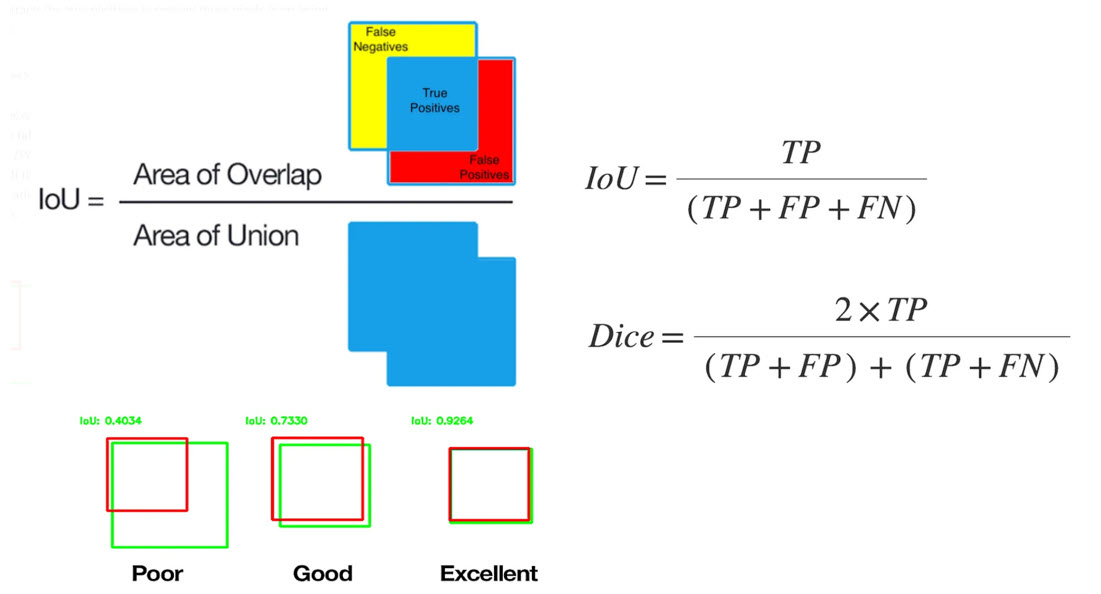
https://www.tensorflow.org/api_docs/python/tf/keras/metrics/IoU
https://karan-jakhar.medium.com/100-days-of-code-day-7-84e4918cb72c
https://medium.datadriveninvestor.com/deep-learning-in-medical-imaging-3c1008431aafThank you for your help
Peter
February 23, 2023 at 2:29 pm #57843Till the next release please use this sequential partial architecture solution (screenshot below)
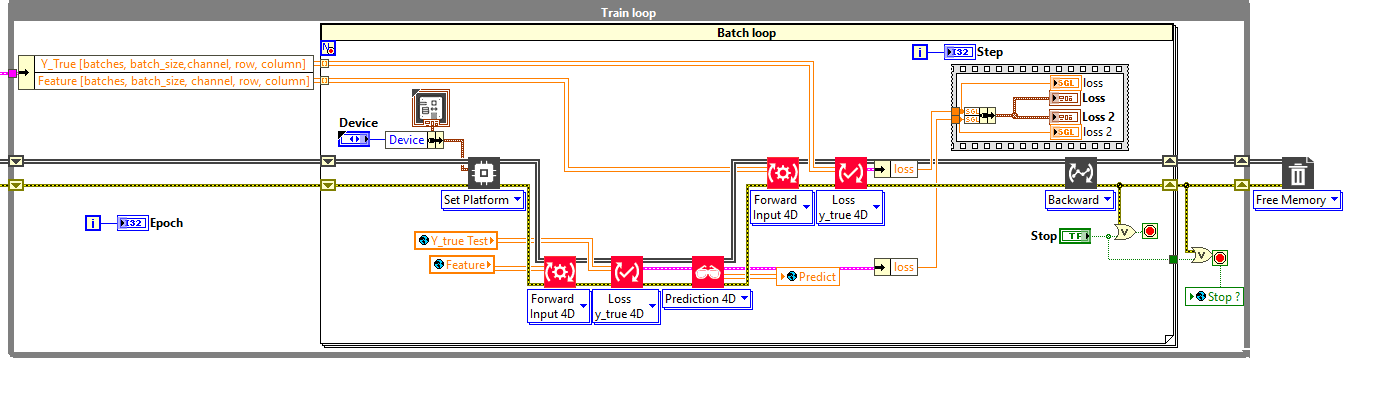
It’s due to a lack inside the cuda memory manager (we fixed it and available in the next release).
-
This reply was modified 3 years ago by Youssef MENJOUR.
February 23, 2023 at 2:34 pm #57844Dear Peter,
I just discuss with one of my engineer we will integrate IoU in the metrics.
To give you a time planification we think it will be released for the 5 March. (It’s too late for the next release –> Coming for 26 february). 🙂-
This reply was modified 3 years ago by Youssef MENJOUR.
February 24, 2023 at 8:08 am #57852Dear Youssef,
you write “Till the next release please use this sequential partial architecture solution (screenshot below)”.
As you can see on my screenshot I use the same sequential architecture as you. Only with vision vi´s instead of picture vi´s.If it helps you I can email you my VI´s
As for IOU and Dice. Beginning of March is totally fine!
PeterFebruary 24, 2023 at 9:10 am #57864Hello Peter,
Take a closer look, my partial solution has a different architecture.
On the current problematic architecture the A and B blocks are in parallel. That’s the problem, the version of HAIBAL you have does not handle this parallelism properly (Fixed and available in next release)
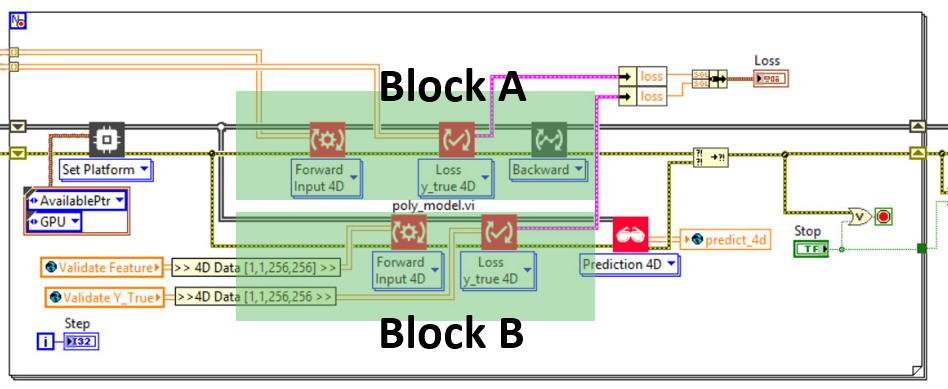
To solve this problem I propose a small modification that will avoid the error.
You have to set the architecture in sequence as follows.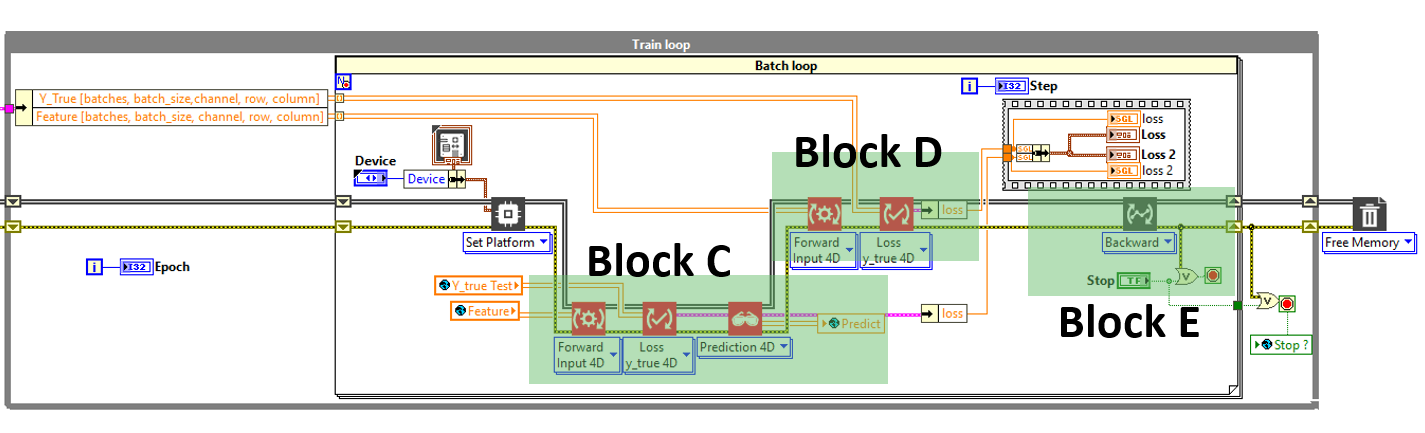
This time we are in sequential, Block C, D and E follow each other and erase the bug at the same time.
This solution is partial because if we want to be optimized in terms of speed we will have to run C and D in parallel (this will allow us to make predictions while training the model in an optimized way).-
This reply was modified 3 years ago by Youssef MENJOUR.
February 24, 2023 at 10:33 am #57896Oh Sorry Youssef! My fault!
I will adjust the code accordingly.Thank you very much.
Peter
February 27, 2023 at 8:09 am #57990Dear Youssef,
Unfortunately I get the same error when running the code sequentially
 February 27, 2023 at 8:14 am #57991
February 27, 2023 at 8:14 am #57991Dear Peter,
Could you please send me your code by mail ?
I will have a look.
Anyway we are finishing the new version of our cuda memory manager that will solve this issu.Could you also tell me which version of HAIBAL is actually running ? Which version of LabVIEW is in use ?
-
This reply was modified 3 years ago by Youssef MENJOUR.
February 27, 2023 at 9:07 am #58015Dear Youssef,
ok I will send you the code by email.
I use Win10, LabVIEW 2021 (I have also LV 2022 Q3 installed) and Haibal 1.2.1.3
I use also a Nvidia RTX 8000 (48 GB)As I wrote in a previous mail your medunet is running without problems
February 27, 2023 at 3:09 pm #58135Dear Peter,
I have good news and bad news.
The bad news is that you are absolutely right, there is a problem with HAIBAL 1.2.1.3 –> tested and I am witnessing the same error.
There is no partial fix with HAIBAL 1.2.1.3 that we can do.
You will have to wait for the next version. 😅The good news is that I just ran it with the latest version of the HAIBAL project and it works fine!!!
So I will have to ask you for a little patience we are checking that all our modifications are working properly, we should finish tomorrow.
I’ll make an intermediate release for you as soon as we finish (it will be only the version for LabVIEW 2021) –> so that you are not blocked in your work. (I confirm you that your code and your project are working properly) —> it work fine with RTX 3900, so with your RTX 8000 it will be ok 🙂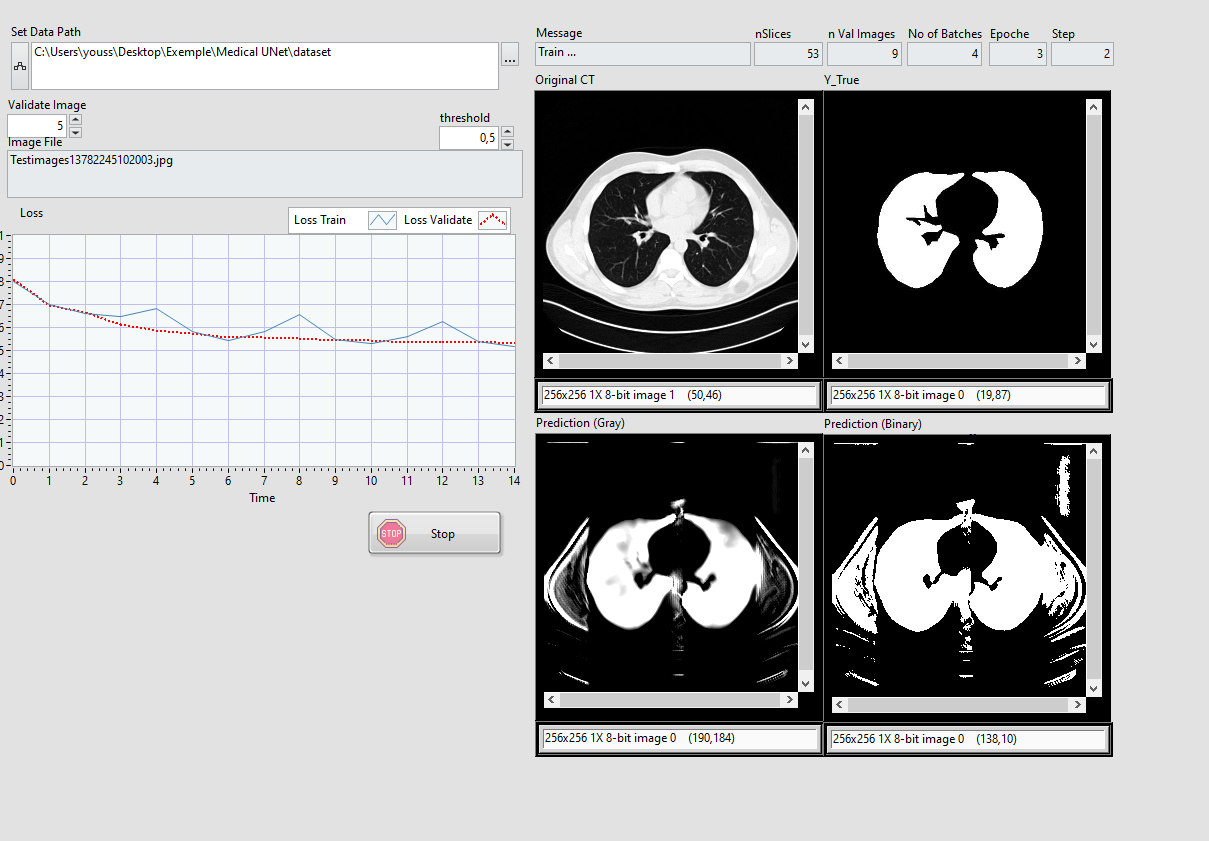
The big release will take place in a week (there will be a lot of changes including the file management in a new format).
I see that you save with the current system that we will abandon because if we update the model the bin will not be readable. The new format (Format h5 used by Keras tensorflow and adopted by us) will avoid this whatever the future updates.-
This reply was modified 3 years ago by Youssef MENJOUR.
February 28, 2023 at 7:48 am #58140Dear Youssef,
OK. This is good news that you found the bug!
I have now also installed Haibal for LV2022 and will then continue programming with LV2022.I’m looking forward to the new big release. 🙂
PeterFebruary 28, 2023 at 8:05 am #58141Dear Peter,
I do not want to block you in your tasks so if it is problematic for you I will make you an intermediate version.
Attention all the same, in the new update, we change completely the system of saving of model and we adopt the format h5 (google keras uses it also) for more flexibility.
Tell me what suits you best, we will adapt accordingly.
February 28, 2023 at 8:16 am #58143Dear Youssef,
I find the h5 format for saving the model very good. This means that h5 models can also be loaded in Haibal.
If you could make me an intermediate version for LV2022, that would of course be great.
Then I could work on a large data set (about 30,000 CT images).Thanks a lot for your help
PeterFebruary 28, 2023 at 8:29 am #58144Dear Peter,
Ok let me finish all the test on memory and we will start a non official intermediary version for LV2022 (i’ll updload the link of 2022 and notify you as soon as we are ready –> compilation take at lease 7 hours because of number of VI so i think in best of case it will be ready by tomorrow)
About Keras, yes in the next release we will be able to load H5 from keras natively in HAIBAL. It mean if you find models in H5 helping you in your work you’ll be able to load them. (And in an other future release we will be able to generate the whole architecture, giving you the possibility to modify it with HAIBAL and keep weights !! 😎)
Our saving file format will be a little different so HAIBAL h5 will not be readable with Keras. (maybe in a future update we will devellop a small tool converter H5 HAIBAL –> H5 Keras “xxx version”)
March 1, 2023 at 8:14 am #58280Dear Peter,
We still have a fix not yet finished inside the HAIBAL cuda memory manager before making you an intermediary release.
All our apologies we trying to finish it by today. Even if it’s an intermediary release it’s a big update.
I keep you informed
Youssef
March 2, 2023 at 1:54 pm #58342Dear Peter,
Just a quick message to inform you that we just finished the verification 🤠. (it was hard ! but now i can say HAIBAL has a verygood memory manager able to make … all architecture you want with no restriction – parallele / sequential).
Now it’s 14.52, compilation will take 8h so we will continu to dev till tonight then i’ll launch during the night a build.
You will have a fixed version by tomorrow morning.
Thank you for your patience.
Youssef
-
This reply was modified 3 years ago by Youssef MENJOUR.
March 4, 2023 at 2:16 pm #58346Dear Youssef,
thanks a lot for your help!
Great job as always.
Peter
-
This reply was modified 3 years ago by
-
AuthorReplies
- You must be logged in to reply to this topic.